Let’s look at AWS Access Keys inside a Lambda function, from how they are populated into the function’s execution context, how long they last, how to exfiltrate them out and use them, and how we might detect an compromised access keys.
But before that, let’s go through some basics. Lambda functions run on Firecracker, a microVM technology developed by Amazon. MicroVMs are like docker containers, but provide VM level isolation between instances. But because we’re not going to cover container breakouts here, for the purpose of this post we’ll use the term container to refer to these microVMs.
Anyway…
Lambda constantly spins up containers to respond to events, such as http calls via API Gateway, a file landing in an S3 bucket, or even an invoke command executed from your aws-cli.
These containers interact with AWS services in the same exact way as any code in EC2, Fargate or even your local machine — i.e. they use a version of the AWS SDK (e.g. boto3) and authenticate with IAM access keys. There isn’t any magic here, it’s just with serverless we can remain blissfully ignorant of the underlying mechanism.
But occasionally it’s a good idea to dig deep and try to understand what goes on under the hood, and that’s what this post seeks to do.
So where in the container are the access keys stored? Well, we know that AWS SDKs reference credentials in 3 places:
- Environment Variables
- The
~/.aws/credentialsfile - The Instance Metadata Service (IMDS)
If we check, we’ll find that our IAM access keys for lambda functions are stored in the environment variables of the execution context, namely:
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
- AWS_SESSION_TOKEN
You can easily verify this, by printing out those environment variables in your runtime (e.g. $AWS_ACCESS_KEY_ID) and see for yourself.
OK, now we know where the access stored keys are stored, but how did they end up here and what kind of access keys are they? For that, we need to look at the life-cycle of a Lambda function…
Access Keys in a Function
Every lambda function starts as a piece of code stored within the Lambda service. When the function is first invoked, it undergoes a cold-start, which creates an execution context for that function before executing it. If the subsequent invocation occurs shortly after, Lambda re-uses that execution context, resulting a much quicker warm-start.
A cold-start involves finding some compute resource within the Lambda service, and creating the container to run our code within those resources. The warm-start simply reuses that container, and is therefore faster. But a cold start isn’t a once-in-a-lifetime event, it occurs fairly often as Lambda purges old containers off the platform to make way for new ones.
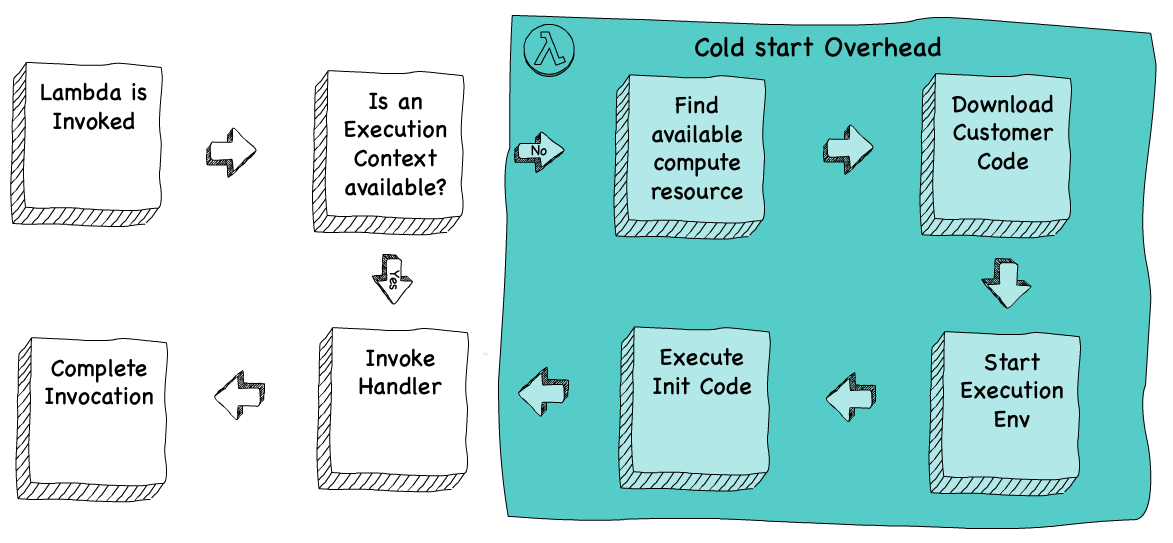
This picture was inspired by a wonderful talk from James Beswick linked here. But we still don’t see any injection of access keys … for that we need to dig into Cloudtrail logs.
In Cloudtrail, we discover that a cold-start doesn’t just create the container, it also creates an sts:AssumeRole and logs:CreateLogStream event. I don’t know precisely where these events occur during the cold-start, but imagine it’s something like this:
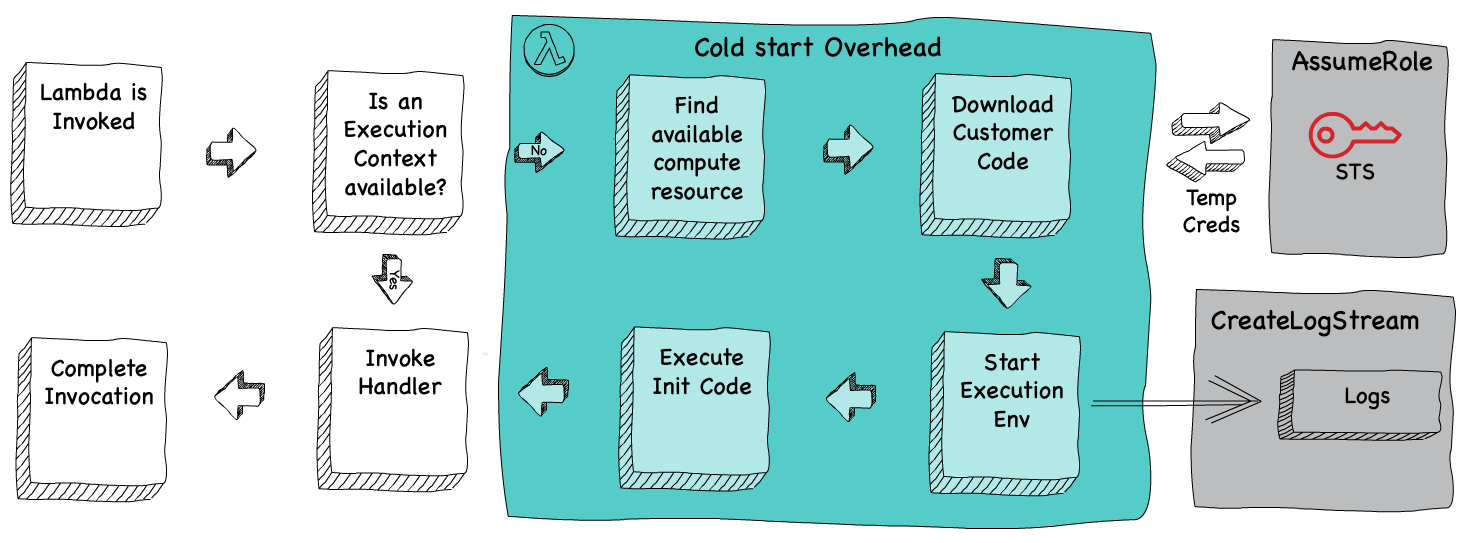
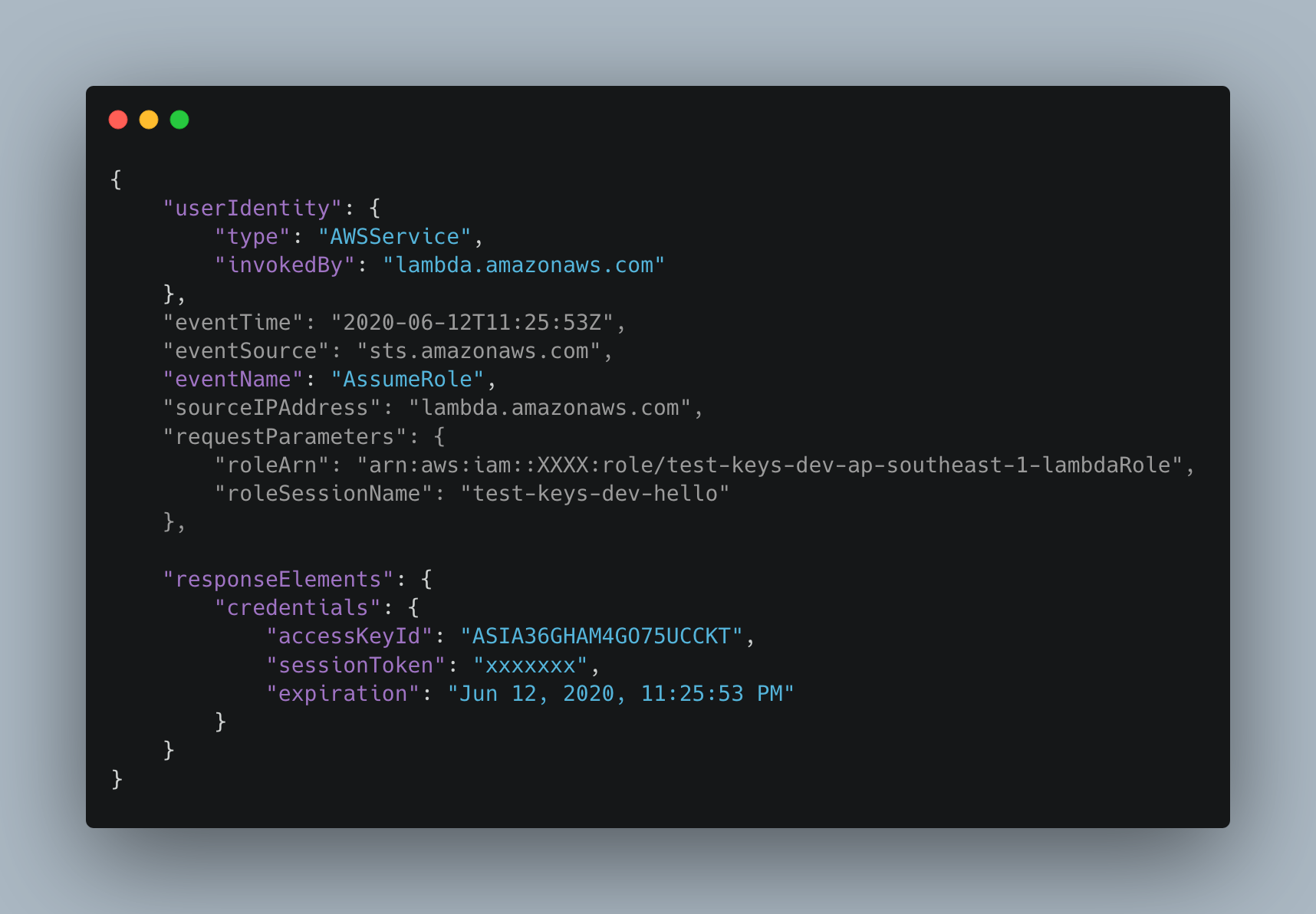
We know from the logs that sts:AssumeRole is invoked by the Lambda Service, lambda.amazonaws.com (not the lambda container!). Here’s a stripped down event from CloudTrail of the AssumeRole, notice the credentials expiration date against the eventTime, and also note that this call was made from lambda.amazonaws.com.
The next event for this function is logs:CreateLogStream, which is executed from the lambda container using the newly minted access keys (from AssumeRole). Notice here we have an actual sourceIPAddress field and userAgent, but more importantly, we can see that the userIdentity.accessKeyId matches the key id from the previous event. Here’s the event:
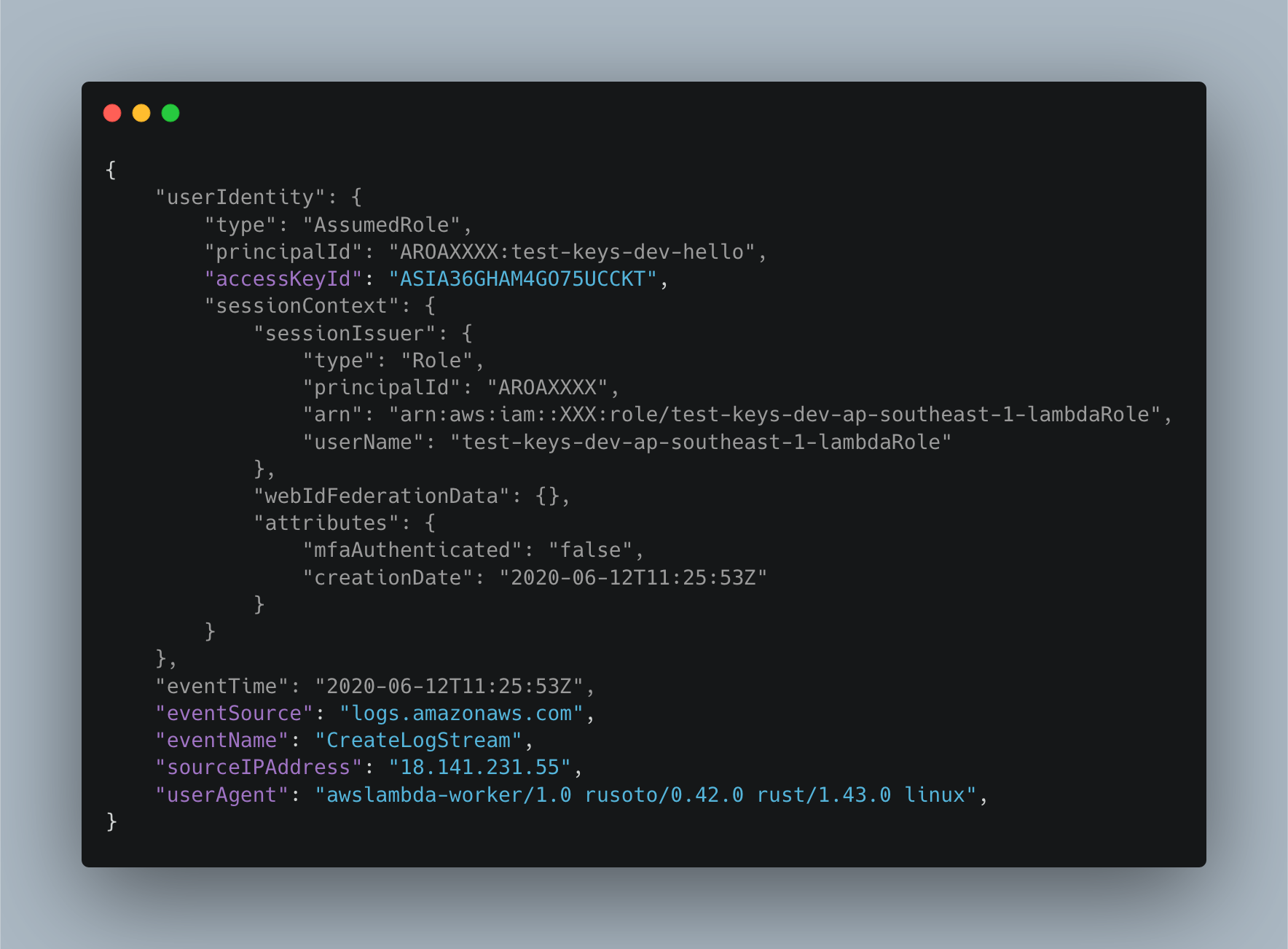
Strangely for my Python function this was executed by a Rust SDK user agent, suggesting it occurs even before the execution environment is setup.
It looks like the Lambda Service, gets Temporary Access Keys from STS, and injects them into the container during a cold-start. From there the container uses those credentials for everything it needs to do, not just creating the new logstream. Here’s an example of the CloudTrail event of the same function Listing all Buckets in an account:
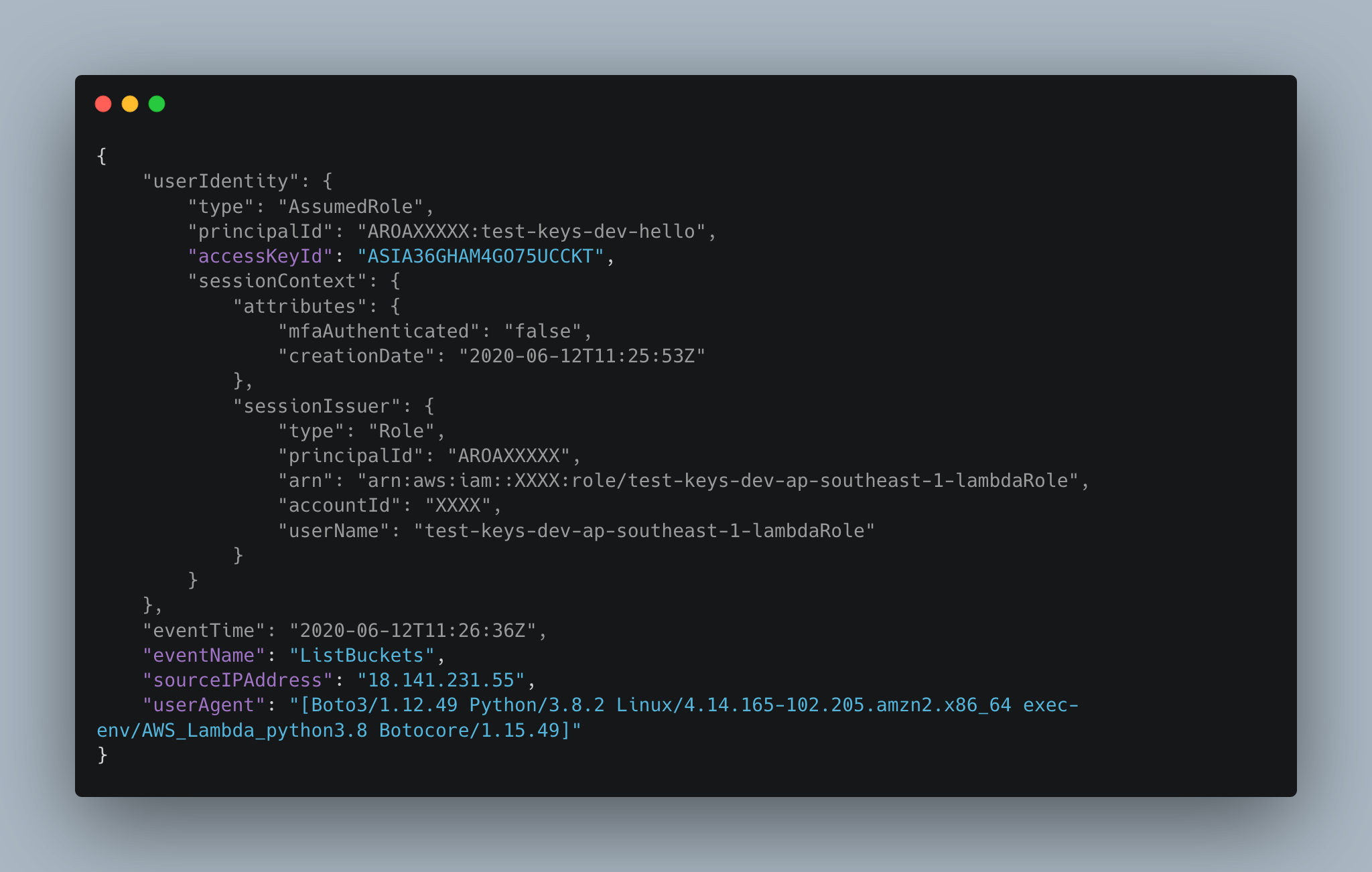
We can correlate them using the $.userIdentity.accessKeyId field, as they’ll be the same across these operations. So we can know that a cold-start generates these temporary access keys, but how are these temporary credentials rotated?
Short answer is … They Don’t!
Access Key Lifecycle
At least from my research, Lambda always requests for 12 hour tokens (which is the maximum duration possible). I’ve confirmed this from other content online as well, including this great talk from ServerlessDays Virtual. And because 12 hours is a STS limit (not Lambda) we see the same behavior for provisioned concurrent functions as well.
My theory is that a Lambda Execution Context wouldn’t last as long as the token, and hence tokens don’t need refreshing.
To test this theory, I created a lambda function that ran every 3 minutes, and kept it running for over 10 hours. The function performed one API Call that listed all the accounts S3 buckets, the actual call is irrelevant, it’s purpose is to help us log the usage of the access key in CloudTrail.
Indeed, I found that the average lifespan of the container came in at just over 2 hours, far shorter than the 12 hour lifespan of the STS token.
| Access Key ID | First Event | Last Event | Duration | Source IP |
| ASIA-1 | 02:31:24 | 04:37:24 | 126 min | 54.255.220.21 |
| ASIA-2 | 04:38:46 | 06:40:24 | 122 min | 18.140.233.226 |
| ASIA-3 | 06:42:11 | 08:49:24 | 127 min | 18.141.233.97 |
| ASIA-4 | 08:52:24 | 10:55:24 | 123 min | 13.251.102.127 |
| ASIA-5 | 10:55:33 | 12:49:23 | 114 min | 13.228.70.250 |
AWS are pretty coy about how long containers get recycled in Lambda, I think it’s down to an algorithm that takes into account the current volume on the entire Lambda service in that region at that instant, and a some other metrics from your functions invocation history. Hence it’s pretty unpredictable, which makes publishing any estimate very hard.
The important piece of information though is that once a Temporary Access Key is generated — it is only used by the exact same IP for all future API calls. There is a tight affinity between these Temporary Access Keys and IP addresses. I assume this is because once a container is created, it is assigned a static IP address that is never changed (but might be shared with other containers).
From the CloudTrail logs, I see that everytime a new sts:AssumeRole event is called for the function, there is a corresponding logs:CreateLogStream event, and the next operation of the function uses the new Access Key ID and has a new source IP. All of this suggest the old container was recycled, and we went through a cold-start.
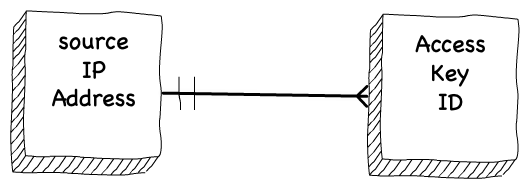
Under normal conditions, an Access Key ID is never shared across multiple source IP addresses. So let’s put this all together shall we.
Putting it all together
It’s a bit hard to make conclusions based on reverse engineering log files, but I’ll go out on a limb and say the following:
- An
sts:AssumeRolecall from the Lambda service is made during a function’s cold-start - The assume Role generates a temporary access key with
- A new Access Key ID
- A new Session Token
- The credentials are injected into the function’s new execution context
- The function then has the credentials it needs for API Calls
- The function execution context will die before the credentials expire
- The behavior is identical for provisioned concurrency function
The temporary access keys are for the Execution Role of the function, which means they are limited to whatever the permissions the role has. Remember lambda functions have a function-policy and an execution-role, these define who can invoke the function and what the role can do respectively. For this, we’re only interested in execution role.
So now we know where the access keys are, and where they came from. How do we exfiltrate them? That’s actually an easy answer.
Any compromise on the function’s code, that would allow access to the environment variables would suffice, because that’s where the keys are stored (unencrypted!). From there we could use a standard boto3 session to impersonate the lambda function from our local machine, or just about anywhere we could run an AWS SDK.
But is there a way to differentiate a legitimate API call from a lambda function vs. a malicious API call using these stolen access keys?
Maybe….
Detecting Stolen Keys
Here’s a call I used from my Macbook using the STS tokens from a function:
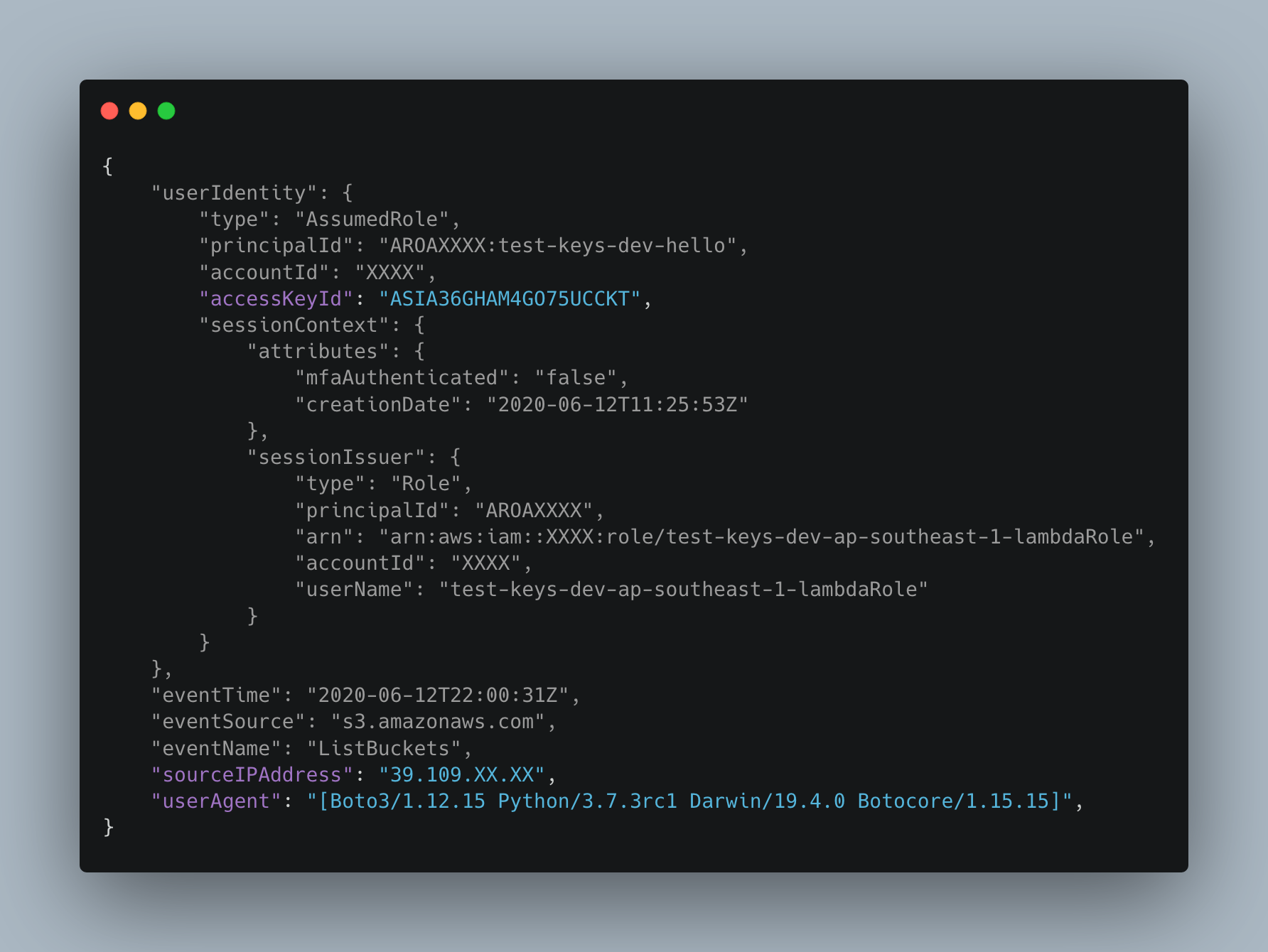
Looking through CloudTrail logs, only two fields differ between legitimate calls from Lambda vs. these malicious calls using stolen creds:
- sourceIPAddress
- userAgent
UserAgent only differs I’m calling an API from my Macbook . But I’m certain this can tweaked (just like browser user-agents can be tweaked) which limits our ability to rely on this field as a detection method.
sourceIPAddress is the most promising field, if we know that temporary access key was assumed by lambda.amazonaws.com, then we can assume that that access key should only be used by AMAZON IP addresses.
But attackers could simply load credentials into a lambda container, and evade detection — fortunately, there seems some restrictions here.
Because a temporary access key has a tight affinity to an IP address, we can be certain that if we detect an access key that was assumed by lambda.amazonaws.com running on multiple different IP addresses, that’s a good sign we need to start worrying.
But after we detect it, there’s the problem of fixing it.
Revoking stolen keys
Firstly, let me say, I’m not a big fan of ‘network’ level protection for serverless — the benefits don’t justify the complexity. Serverless resources like DynamoDB, StepFunctions, and EventBridge don’t support resource-based policies, and can’t be restricted to specific VPC-endpoints like S3 or EC2.
You can allow your VPC to connect to DynamoDB, but you can’t limit DynamoDB to only your VPC. The only mechanism we have is IAM.
Plus stolen credentials from a function might look cool, but practically this has no value, after all if attackers have already compromised your lambda to the point of dumping environment variables — chances are they don’t need to exfill those credentials to poke around.
With those practical considerations in mind, we need two steps to fix this issue, the first is a pro-active measure to ensure function get its own IAM role, with scoped down permissions for only what the function needs to do.
This means that even if the access keys of a lambda function were compromised, the attackers couldn’t do anymore damage, then they could have already done.
The second fix, is about addressing the problem of the specific lost key. For this we need to fix the compromised function first — revoking any specific access key isn’t going help, as the attackers could compromise the same function again to obtain newer access keys, just like a genie that grants more wishes.
Assuming we plugged the hole in the function, we still have the issue of a 12-hour token, that (as we saw previously) can live long past the expiration of the function.
We can’t revoke the temporary token itself, even if we knew the exact access key with ID, AWS doesn’t have this capability (AFAIK). Instead, we could revoke the IAM Role that the token belongs to. This is tough, because revoking that role will damage all instances of your function as well.
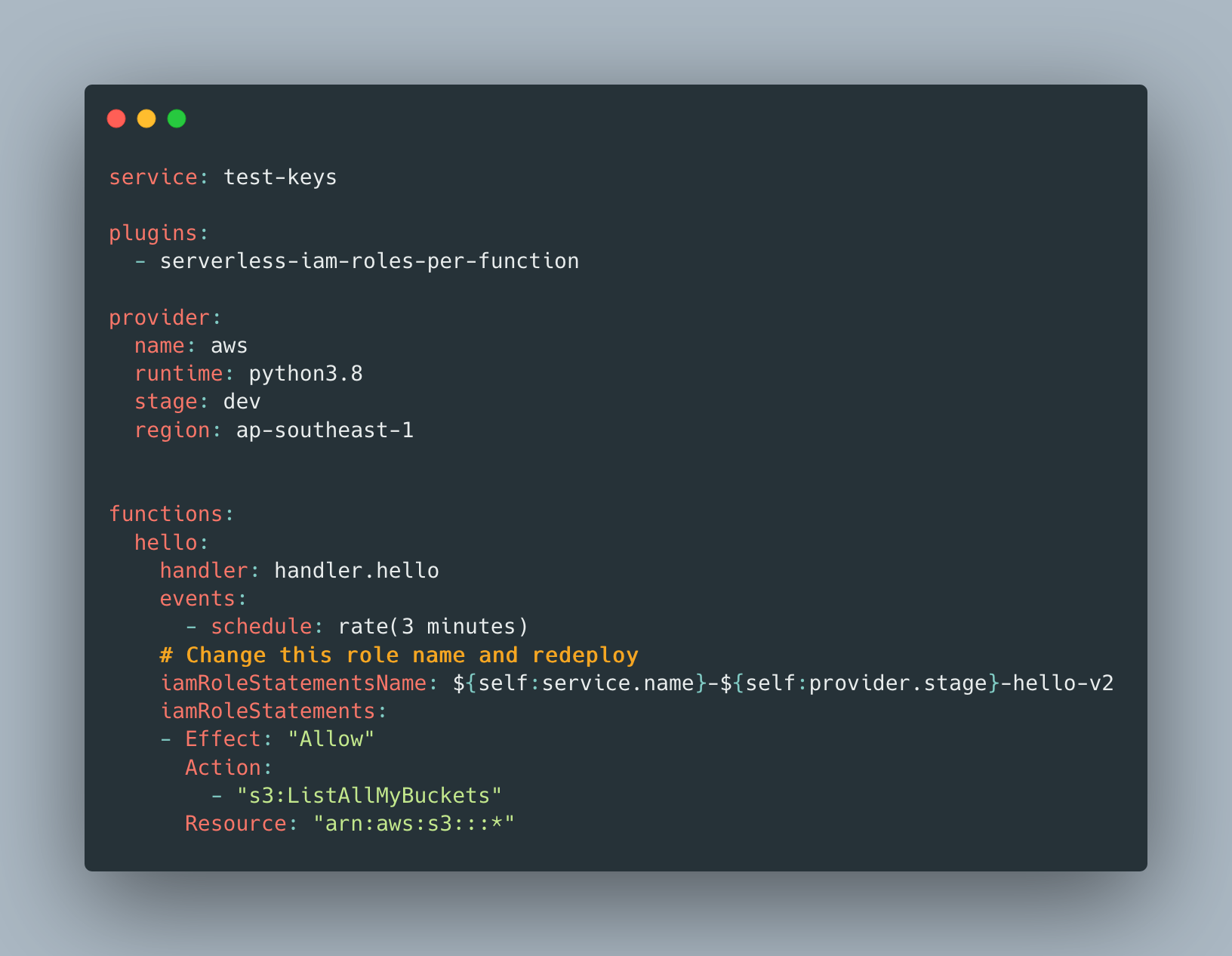
Fortunately, if we use Serverless framework, and the IAM-Roles-Per-Function plugin, we can rename the IAM role of the function, and re-deploy the stack. This will invalidate the previously issued tokens (as the role would be deleted), and redeploy a new version of the function pointing to the new IAM role. Hence, we invalidate the old tokens, but keep our current function executing correctly.
Conclusion
To me, Lambda functions are the way future compute will be built around. We’ve just started this journey, and the hype train is on it’s way. But just because AWS own the servers, doesn’t mean we should remain blisfully unaware of what goes on under the hood.
What I’ve found is understanding how Lambda works (even though we’re not orchestrating it) is a worthwhile investment of time, and helps me write better functions. Hopefully this post helped you to.
Note: The final solution depends on sts:AssumeRole returning a unique accessKeyID everytime. This might not be the case, as I see no guarantee of this anywhere in the docs, but from my practical testing this has always been the case.
Free resource to help play around in a lambda at http://www.lambdashell.com