GitHub actions is the new kid on the workflow block.
It allows users to orchestrate workflows using familiar git commands like push & pull requests, and un-familiar GitHub events like gollum, issue creation and milestone closures.
In this post, we’ll use GitHub actions to orchestrate a build pipeline that will deploy lambda functions using the Serverless framework. There’s a lot of tutorials that cover the basics of doing this, but we’ll dive deeper and cover off framework plugins and deploying to different environments using feature branches.
A working example of all this can be found in this GitHub repo here.
GitHub Actions basics
Let’s start with the basics — in order to create a build pipeline in GitHub, you’ll first need to define the workflow via yaml files in the .github/workflows directory of your repository.
Each workflow file consists triggers, jobs and steps.
- Triggers define when to execute jobs.
- Jobs define what steps to execute (with flow logic)
- Steps are the granular commands of each job.
For a simple serverless deploy project, we can use the following workflow file:
If you put this yaml file into .github/workflows/main.yml, then a push to master will trigger it — which in turn will deploy your serverless.yml configuration using serverless deploy.
So far, so good, but there are already good post online for basic deployments like this, so let’s shift our gears by including framework plugins.
Using plugins
Plugins are a mixed-bag with any framework. On one hand, they add amazing functionality by leveraging the community — but on the other hand, they introduce lots (and lots) of security, stability and trust issues.
Serverless plugins aren’t that bad though ( at least compared to something like wordpress) — so far I’ve had only good experiences with them — although I still limit them wherever possible.
But that still means I use them, and need a pipeline that supports them.
So how do we include serverless plugins? Simple.
Include a package-lock.json file in our deployment, and the previous workflow file would work just fine In my example, I installed two serverless plugins:
$ npm install --save-dev serverless-iam-roles-per-function $ npm install --save-dev serverless-step-functions
As long as the corresponding package-lock.json file is located in the working directory of serverless.yml file, the framework will deploy with the plugin installed. You can view the package-lock.json file here.
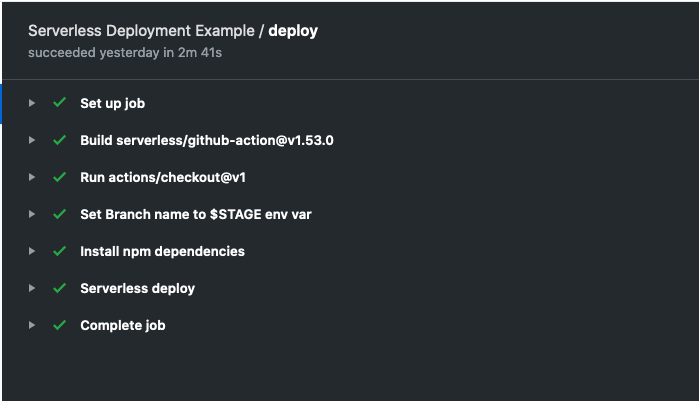
With that simple step out of the way, let’s now switch our attention towards setting up our pipeline for deploying to different environments.
Stages and Environment
This is where things get a bit clumsy, GitHub actions work off Git version control, and the triggers are limited to Git actions — as far as I can tell you can’t simply trigger a job by pressing a button. Everything has to be done via GitHub and the triggers already specified.
You can circumvent this issue by creating a dummy deploy, using something like this:
$ git commit --allow-empty -m "trigger GitHub actions"
But you’d be trying to hack around Git rather than embracing it. Instead, I think we should approach this problem by trying to embrace the wonderful harmony of Git and serverless all at once.
With serverless, each additional environment of lambda functions cost nothing. Even additional SQS queues, DynamoDB tables and S3 buckets would add pennies on your AWS bills. Furthermore, the serverless framework actually helps us create these separate environments via the stages.
Each stage in the framework is an independent (namespace separated) environment, containing a copy of all deployed resources. Under the hood, the framework uses Cloudformation to deploy, and includes the stage name in the resources in the stack to ensure uniqueness.
Here we can see how the harmony might work — if we ensure that branches in git corresponds to stages in framework, we can generate unique environments for each branch, and have that propagate all the way from feature branch to master.
The main caveat, is that we should limit our tinkering with our environments outside of this pipeline (and that’s true of any pipeline), if you deploy using the pipeline, but modify configuration manually, the system breaks down quickly! Use the console/CLI as read-only mechanisms, everything else should go via the pipeline.
Feature Branches and Serverless
Imagine we had a standard feature-branch strategy as below:
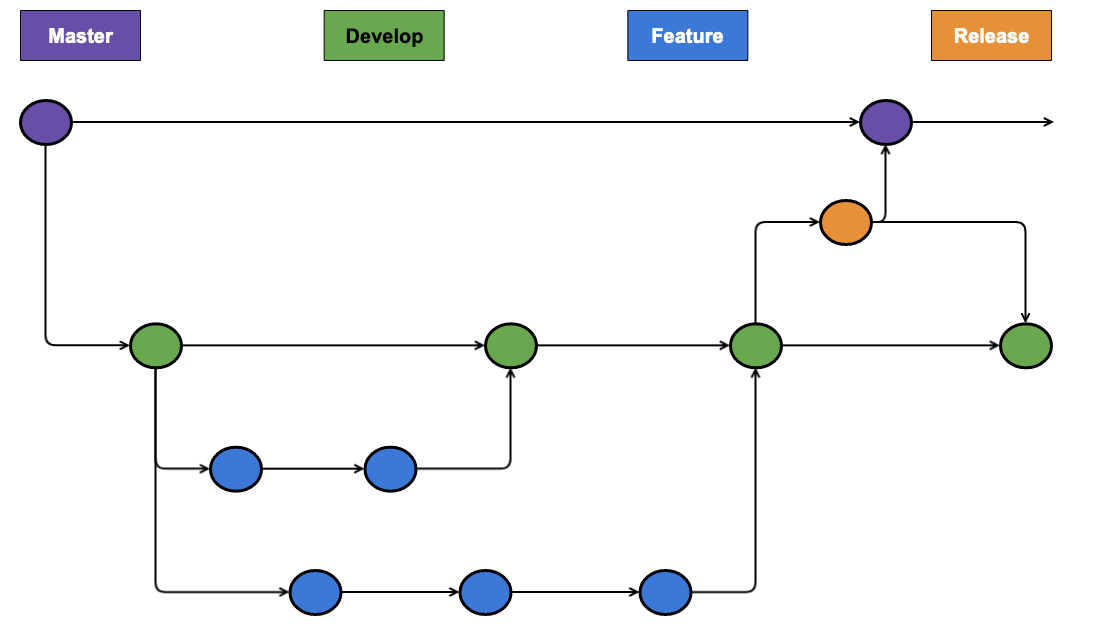
In order to ensure that each branch in the repository corresponds to a different environment, all we need to do is modify the Github actions workflow to specify the stage on each deploy.
Typically, we’d deploy a stage via serverless framework using the following:
$ serverless deploy --stage dev
But an easier way for us is to set the $STAGE environment variable. If we set the workflow to set $STAGE to the name of the current branch, then the framework will deploy all branches into their own stages.
Doing this took some digging around in docs. But each time a Github action is invoked a $GITHUB_REF environment variable is populated, which contains the name of the current working branch. To get the branch name out of this variable — and then setting the $STAGE environment variable we have to do something like the below:
When combined with the previous example, we can trigger a build on every commit to every branch in the repository — which in turn will deploy environments per branch into our AWS account, like below:
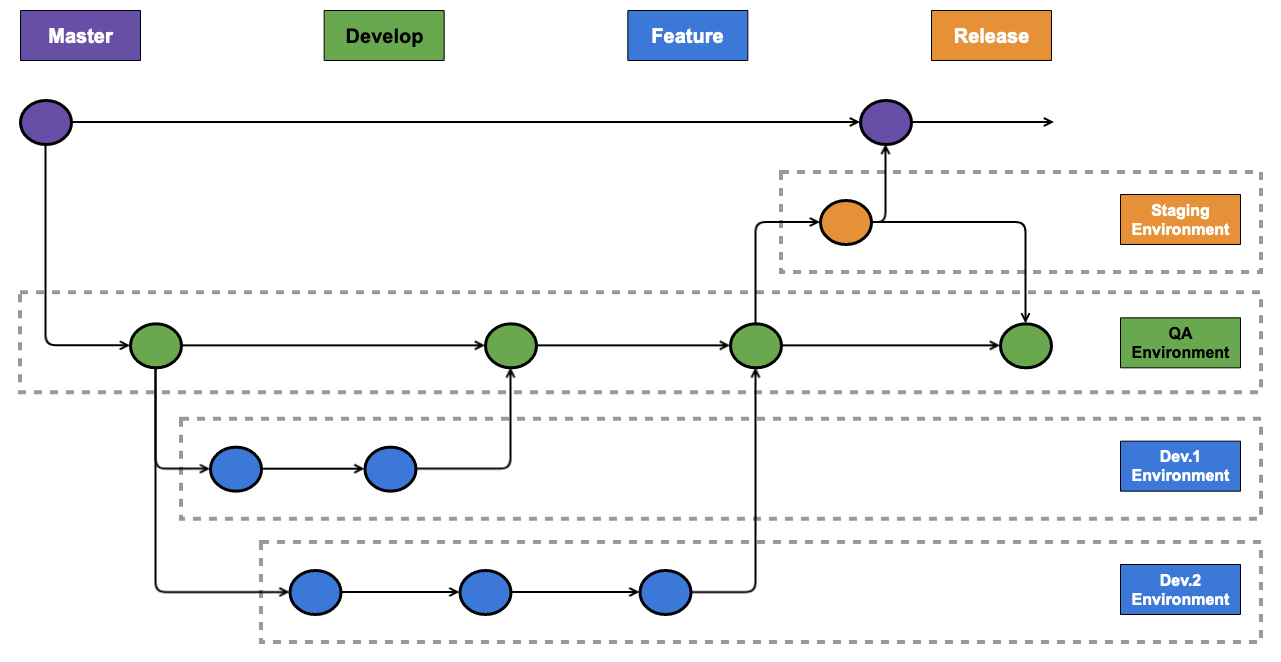
But at some point, presumably after the 10,000th Jira story is closed, we’d want to clean up those environments …. so let’s move onto deletion and environment cleanup.
Cleanup
What Git giveth, Git can taketh away!
– Keith
Logically, if a new branch creates a new environment, then a deleted branch should remove the environment.
For this we can use serverless remove, but we’ll need two minor tweaks.
First we need to setup a trigger for delete (instead of push), so that the job gets triggered on a deletion of a branch.
Second, for some strange reason, the $GITHUB_REF variable during branch deletion refers to the default branch of the repository (instead of the deleted branch). Hence, we need to dig deeper into the innards of GitHub actions to extract the name of the deleted branch during a deletion trigger.
Every github action populates a json file into the running container with the full event data that triggered that action, this file is known as the github context. Because the file is json, we can use jq to extract specific fields of that event including getting the name of the deleted branch:
This way, once a branch is deleted, a job is triggered that deletes the environment tied to that branch, using serverless remove.
Hence, as long as our repository is pruned of these branches every once in a while, we’ll reduce clutter in our AWS account as well. Now we have an account with environments for each branch, and maybe even a develop and master branch — what about pushing this to production?
Branches vs. Repos
Here’s a question….
Can we run GitHub actions for production and development environments from a single repo — yes!
Should we do that? — NO!!!
Typically, for security (and other!) reasons your development and production environments will live in different AWS accounts — which means they’ll get a different set of AWS Secrets. These secrets are stored in Github for our pipelines to consume.
As far as I could tell, there’s no way to limit secrets to specific branches or users. Hence, any user could modify the workflow files in their branch, and trigger a deploy to production utilizing the AWS keys in the repo.
After all the current executing workflow is the one defined in your current branch. So if you had your production key named AWS_SECRET_KEY_PRODUCTION there’s nothing to stop me as a developer working on feature branch to use that key to deploy into prod.
So instead, we should keep the production keys in a separate (forked?) repo, and only deploy to production from there. Obviously this repo should be tightly controlled, and presumably will only accept pull requests from the release or QA branch of a developer repo — I’m not sure I have an elegant solution here.
Typically, you wouldn’t have 2 separate code-repos, but you would have two separate build pipelines, and since in Github Actions the repo and pipeline are the same thing — this might make sense.
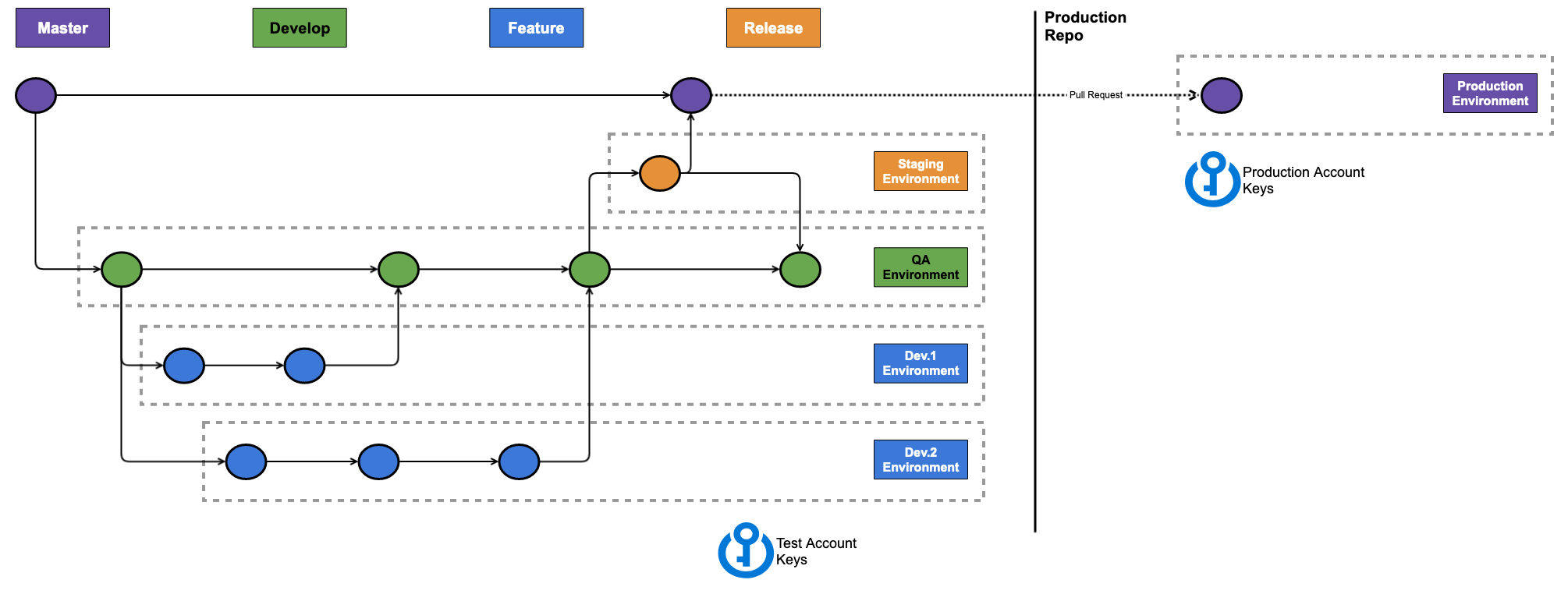
Also, I’m still torn about how hotfixes might work in the solution above. It’ll be a pretty slow process to modify the Release branch, and then perform 2 pull requests, but perhaps that’s OK.
Conclusion
Github actions is really cool, but it’s a workflow tool that may work well as a build pipeline. It misses the mark in some places, and felt a bit un-finished to me — at least for this use-case.
But it does have magnificent promise, after all your code is already there — and you’re already using it for issues/pull requests. You owe it to yourself to at least try it.
The best thing about GitHub actions though, is that it is SaaS offering — no more mucking around with Jenkins configs, and no maintaining servers with provisioned capacity or storage issues. It fits in well with our serverless paradigm and works better than most other build pipelines, and I can easily see a bigger community forming around this than for something like Travis or CircleCI (don’t @ me).
Sometime later, I hope to include tests as part of the build pipeline, and some Terraform scripts for our deployment as well.
TL:DR
One thing that frustrated me about the GitHub actions was the fact that it built a ephemeral container **everytime** we made a deploy — and for some reason that container wasn’t cache-able.
Which meant every build took at least ~45seconds just to get that container ready. In addition to that — serverless framework uses cloudformation, which means the bulk of it’s time is spent waiting on Cloudformation to deploy (another ~40seconds to deploy). Even for fairly simply deployments it can take 3-5 minutes end to end.
You can actually shorten this tremendously, by skipping the serverless action, and installing the framework yourself into the container. This way, you can cache the npm modules, and cut down the build time by 1-2 minutes.
Or you could just run unit test, and even deploy locally from your machine, and only push to the build pipeline once everything is ready — although this is prone to error, as a missed stage name will over-write an already existing stage.
Even longer stop reading
The example repo here has all the code, and with one small change.
Instead of using the serverless github actions in the recommended way:
serverless/github-action@master
I use:
serverless/github-action@e17abe72d4969e86cb53576ade34e95c40362f0e
to avoid a security issue highlighted here.