Lambda functions are awesome, but they only provide a single dimension to allocate resources – memorySize. The simplicity is refreshing, as lambda functions are complex enough — but AWS really shouldn’t have called it memorySize if it controls CPU as well.
Then again this is the company that gave us Systems Manager Session Manager, so the naming could have been worse (much worse!).
Anyway….I digress.
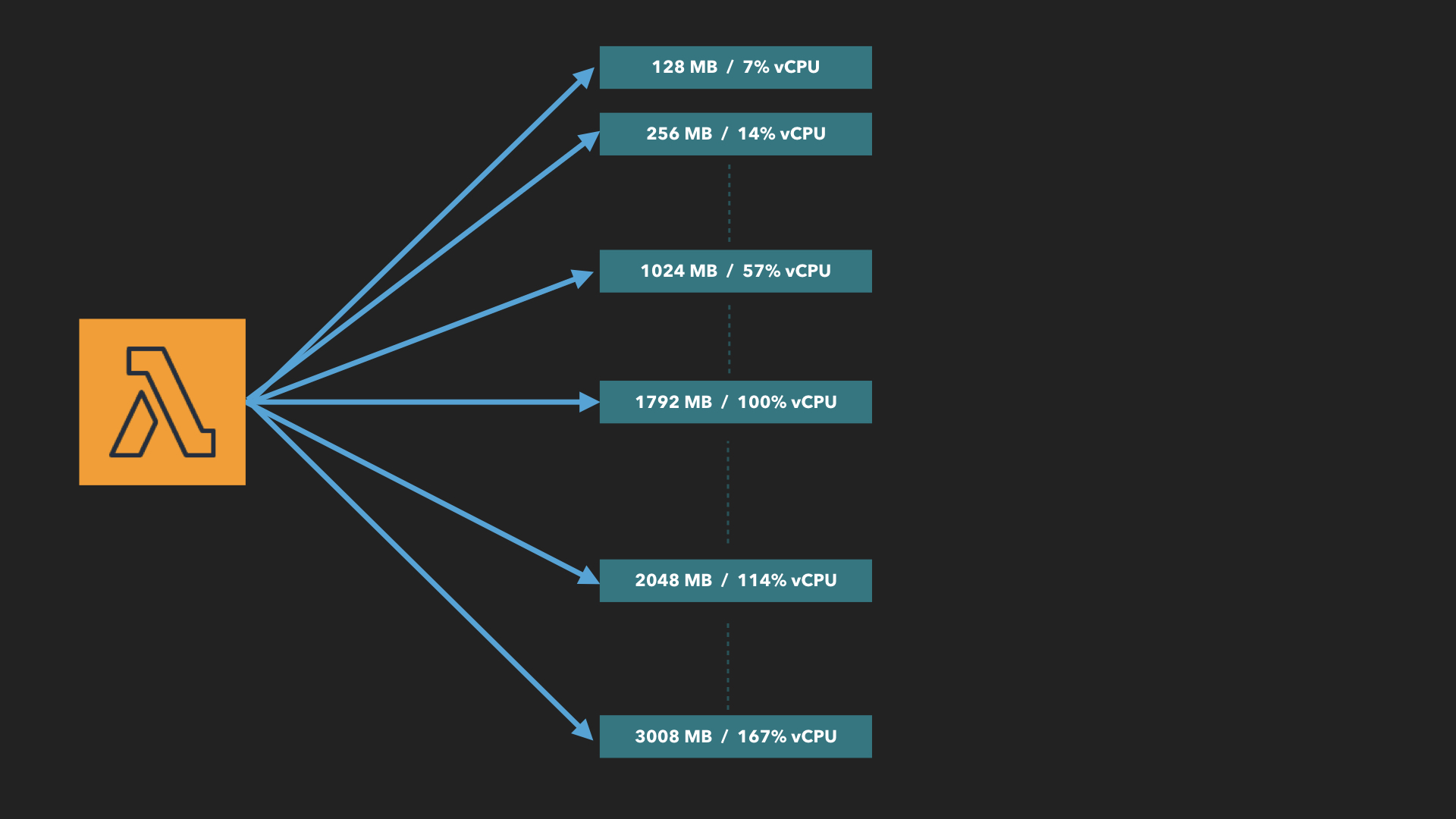
The memorySize of your lambda function, allocates both memory and CPU in proportion. i.e. twice as much memory gives you twice as much CPU.
The smallest lambda can start with minimum of 128MB of memory, which you can increment in steps of 64MB, all the way to 3008MB (just shy of 3GB).
So far, nothing special.
But, at 1792MB, something wonderful happens — you get one full vCPU. This is Gospel truth in lambda-land, because AWS documentation says so. In short, a 1792MB lambda function gets 1 vCPU, and a 128MB lambda function gets ~7% of that. (since 128MB is roughly 7% of 1792MB).
Using maths, we realize that at 3008MB, our lambda function is allocated 167% of vCPU.
But what does that 167% vCPU mean?!
I can rationalize anything up to 100%, after all getting 50% vCPU simply means you get the CPU for 50% of the time, and that makes sense up to 100%, but after that things get a bit wonky.
After all, why does having 120% vCPU mean — do you get 1 full core plus 20% of another? Or do you get 60% of two cores?
It’s a complex topic, that our friends in the server-ed world have struggled with for a long time, EC2 has the T2 instances with burst performance working on exactly the same concept of percent points of a vCPU. In effect, AWS can actually allocate vCPU time dynamically to your lambda function across both the cores depending on your consumption pattern.
1vCPU can either be 100% of one vCPU, or 50% of 2vCPUs — or any combination across the cores that add up to a full 100%. It purely depends on your usage pattern.
AWS think about this from an economics and financial standpoint — i.e. they allocate vCPU credits to you — which you can use across both cores at every lambda size any way you like!
That’s right, because even at 128MB, lambda functions are deployed with two CPUs — regardless of memorySize.
But what does this mean to us?
If you increase the memorySize of your function, you’ll get a CPU performance boost — but only until 1792MB. After that, there’s no point allocating more memorySize, unless the function has multi-core capability.
Because if you’re consuming compute on just one-core, the maximum theoretical limit is 100% vCPU, allocating more is wasteful, which is what happens after 1792MB.
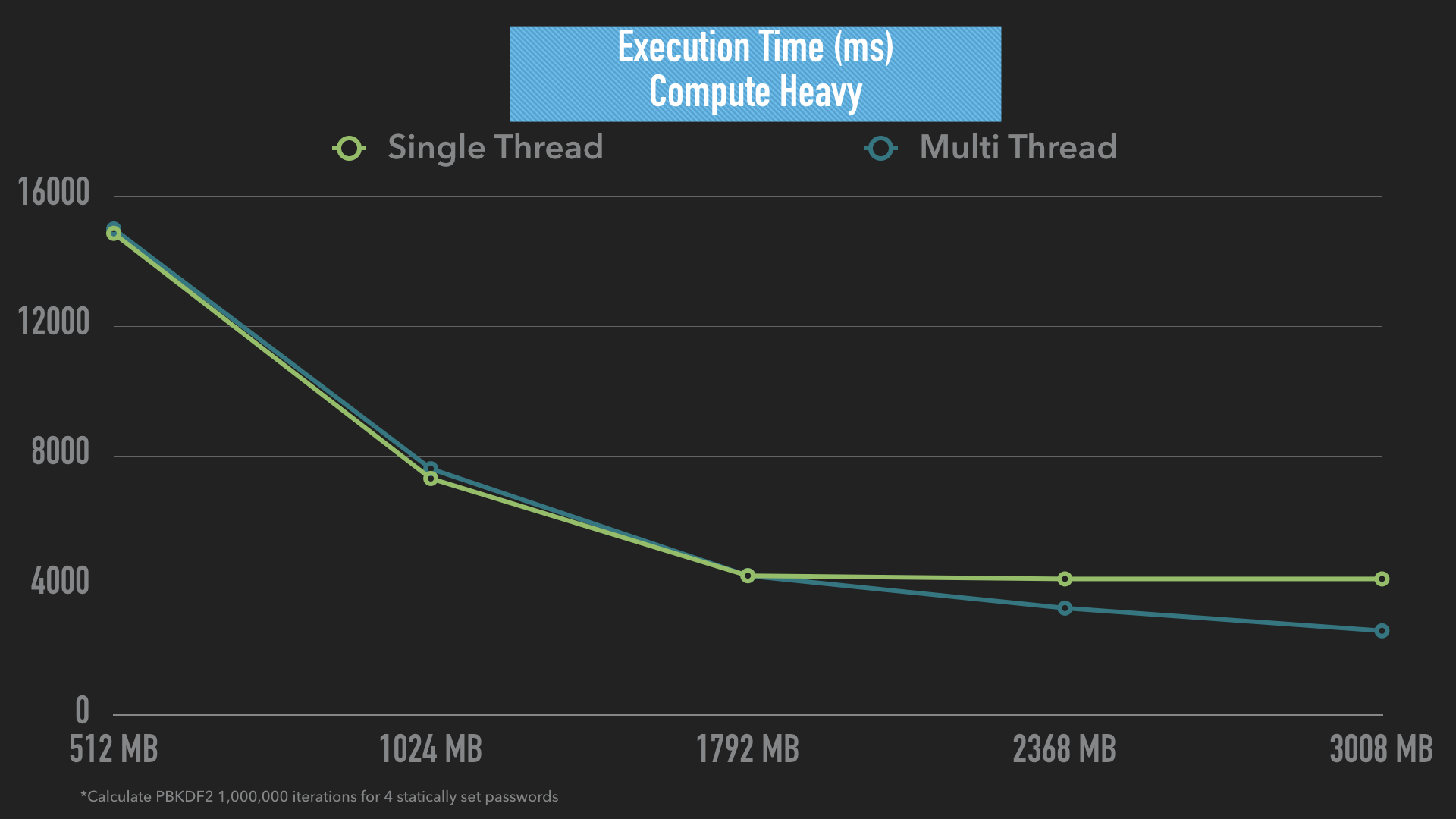
The following diagram shows a simple compute-intensive function of calculating 1,000,000 iterations of PBKDF2 on 4 different strings. The results are exactly as we expect (well sort-off). At memorySize of 1792MB, multi-threading the lambda has no performance gain over single-thread, but after 1792MB, the effects can be seen.
More importantly, a single-threaded lambda function won’t perform any better for compute jobs once you hit 1792MB. Finally, even at 3008MB, we do not see a 67% improvement in performance — in this scenario at least it’s just ~40%.
But lambdas very rarely perform purely compute operations, they usually have a mixture of compute and network (rest calls with boto3 for example), so what would a highly intensive network load look like? Well something like this…
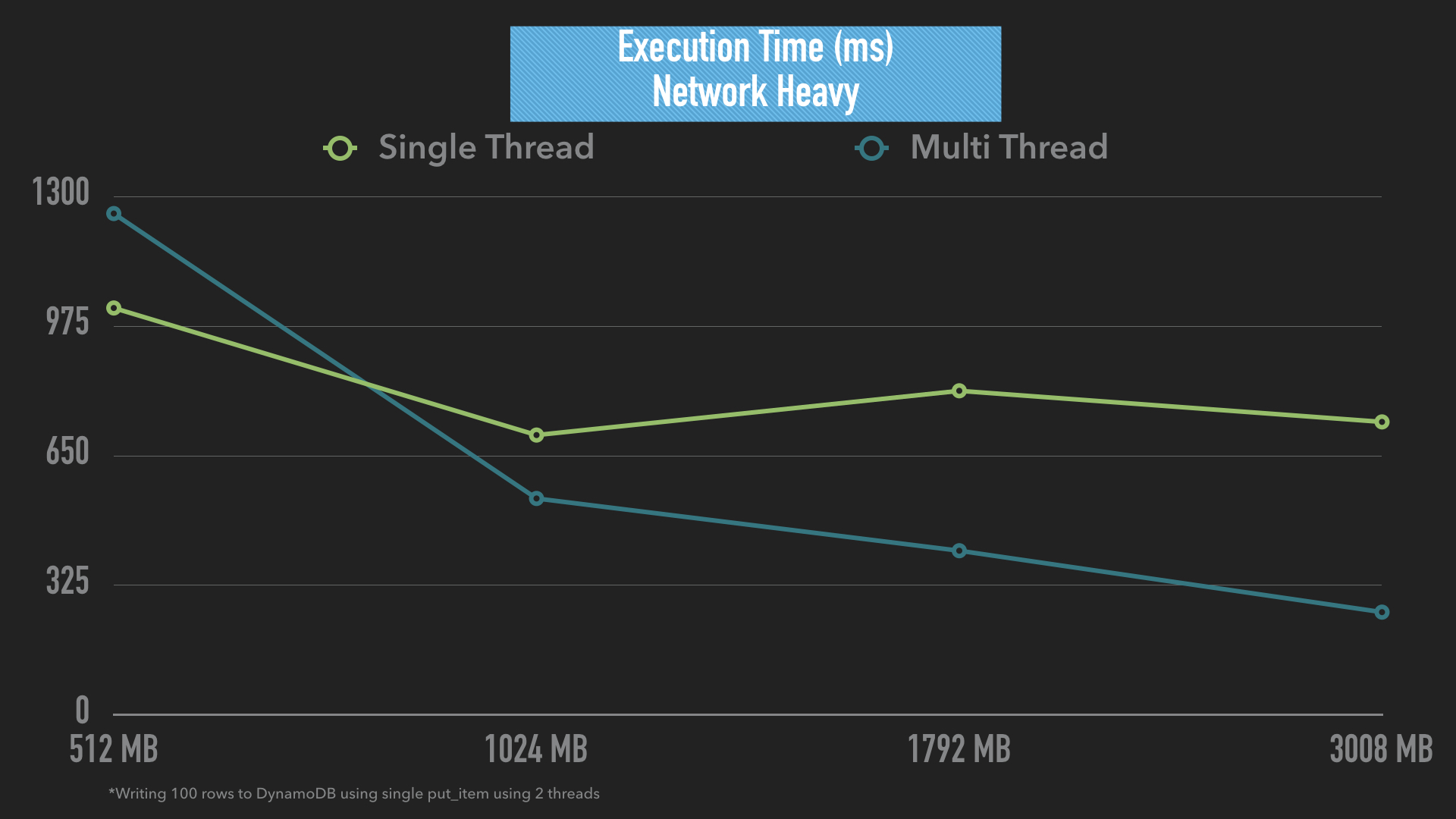
This job wrote 100 items to a dynamoDB table, one item at a time (it’s very bad practice, but a good test case for this example). At the lower end of the spectrum ~512MB, the single threaded lambda does better than multi-threaded. We’d expect this, since with just ~33% vCPU, the over-head of multi-threaded actually slows down performance rather than improves it.
But even at 1024MB, we see a significant increase in lambda performance — what gives? Network jobs are high latency, and having multi-procs does help significantly even if you don’t have 100% vCPU — remember you still have 2 cores.
At 3008MB, you now have roughly 80% of two cores, and can actually multi-proc even better. But remember, the best solution for writing 100 items into DynamoDB is batch-writing :).
Anyway, all this is complicated — but the lesson is that you can’t simply up your memorySize to get a performance boost, and that you can get a performance boost by multi-threading functions even before the magic number of 1792.
To properly size your funtions — you can use lumigo-cli, which works with powertune to spin up a step functions and runs your lambda across multiple memorySize to report which is faster/cheaper.
Remember, Lambdas are charged per GB-s, and sometimes allocating twice the memory will not only save you twice the time, but cost you nothing extra. So when sizing lambda functions, remember that more can sometimes mean less.