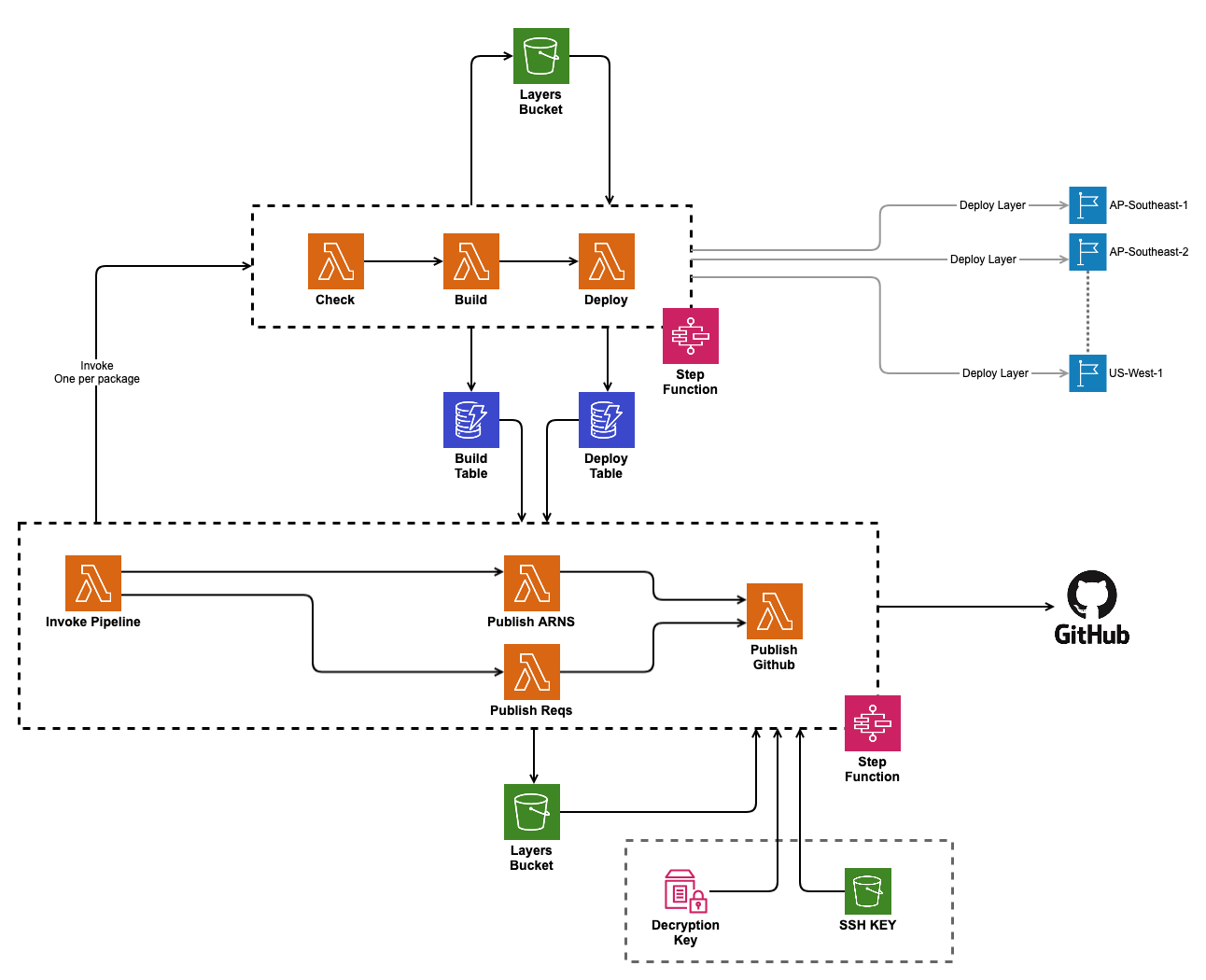
I’ve been bitten by the serverless bug lately, and just completed my latest hobby project this week. It’s a fully serverless pipeline that builds python packages as Lambda layers — and it uses Lambda functions to do so.
As a quick side-note, before we dive into this intro, Lambda layers are simply zip files that get extracted into the /opt directory of your lambda function’s container. This is a special directory because it’s included in various paths including:
/opt/binis in your binary $PATH/opt/libis in your $LD_LIBRARY_PATH/opt/pythonis in your $PYTHONPATH
Hence by packaging your zip files with the right folder structure you can populate your lambda function with binaries, libraries and even python packages and re-use that across multiple functions efficiently (build once, deploy many) and explicitly (your serverless.yml file will contain details of which function uses which package)
Black-belt lambda users are already aware that your lambda functions code exists in the /var/task directory, where binaries and packages can already be placed to be executed. But uploading binaries and packages together with function code is considered bad practice. (at least I consider them bad practice)
For one, going down this path typically necessitates every function in your app having the same packages bundled in, which is inefficient and poses some security challenges as well. Not to mention the performance hit you get from having larger function sizes.
Also, deploying packages or binaries whose sizes range in MBs, together with function code that typically range in the KBs is a slow process. Don’t underestimate the amount of testing you’ll have to do on AWS itself, and having a slow deploy time will really hurt — local deploys only go so far.
Building Layers with Lambdas
But let’s keep the layer preaching for later, for now, I’m assuming you’re already a lambda layer convert. Typically, lambda layers get built on Docker containers — the guys over at lambci have done phenomenal work in getting docker containers that mimic the actual lambda environment on which you can build your binary layers or python package layers.
But I wanted to take things one step further. I wanted to build the layers themselves using nothing but lambda functions. After all, the only reason we needed the containers was to mimic the layers own run-time environment (specifically the OS).
You know what else shares the same run-time environment as Lambdas — Lambda functions!
Hence it’s reasonable to expect, that you can actually build lambda layers using lambda functions — and it turns out for Python Packages this is not just possible, it’s probably the best approach to take.
Lambda functions have limits, for example they only have one writeable directory — /tmp , which makes things a little bit more complicated than buidling in a docker container, but once you overcome this tiny hurdle, building the layer itself isn’t too hard.
Lambdas into pipelines
Turns out, building the lambda layers themselves is kinda easy, but doing it in proper structured way took time. Keeping track of literally thousands of layers is not easy task, which required learning how to ‘properly’ model data onto a nosql database like DynamoDB.
I also discovered the true power of Step Functions, and how immensely helpful they are when trying to orchestrate lambdas together. I’m now a firm believer that step functions are the micro-service layer, and lambdas are just the nano-functions within them.
Finally, I deep-dived into lambdas again, specifically the Python 3.7 runtime — and even used a custom bash runtime for one of lambda functions to push data onto the GitHub repo. Learning along the way, things like securely storing ssh keys for git, and how lambda can retrieve them.
Over the next few weeks, I intend to write a series of post covering what I learnt, both for my clarity and to share with the wider serverless community on the lessons I learnt.
Klayers Part 1: Building Python Packages with Lambda
Klayers Part 2: Deploying Lambda Layers globally
Klayers Part 3: Step Functions are freaking awesome!
Klayers Part 4: DynamoDB data modelling
Klayers Part 5: Securing SSH Keys for Lambdas
Klayers Part 6: The Bash custom Runtime
Klayers Part 7: Above and beyond …
For now, if you’re interested in using one of the nearly 50 layers I’ve built (available in all AWS regions except China), head on over to the GitHub repo here for more info.
Here’s a sneak preview of the architecture of the build pipeline: