At the end of 2018, AWS introduced custom runtimes for Lambda functions, which provided customers a way to run applications written in languages not in the holy list of the 'Official AWS Lambda Runtimes' which include a plethora of languages. It has 3 versions of Python, 2 versions of Node, Ruby, Java, Go and .NET core (that's a lot of language support)
Security-wise, it's better to use an Official AWS Lambda runtime than it is to roll your own. After all, why take ownership for something AWS is already doing for you -- and for free!
But, as plentiful as the official runtime list is-- there're always edge-cases where you'd want to roll your own custom runtime to support applications written in languages AWS doesn't provide.
Maybe you absolutely have to use a Haskell component -- or you need to migrate a c++ implementation to lambda. In these cases, a custom runtime allows you to leverage the power of serverless functions even when their runtimes are not officially supported.
Bash Custom Runtime
Which brings us to the topic of today's post, the bash custom runtime.
For Klayers, I needed a way to update a github repo with a new json file every week -- which can be done in python, but no python package came close to the familiarity of git pull , git add and git commit.
So rather than try to monkey around a python-wrapper of git, I decided to use git directly -- from a shell script -- running in a lambda -- on the bash runtime.
So I pulled in the runtime a github repo I found, and used it for write a lambda function. Simple right? Well not entirely -- running regular shell scripts is easy, but there are some quirks you'll have to learn when you run them in a lambda function...
Not so fast there cowboy...
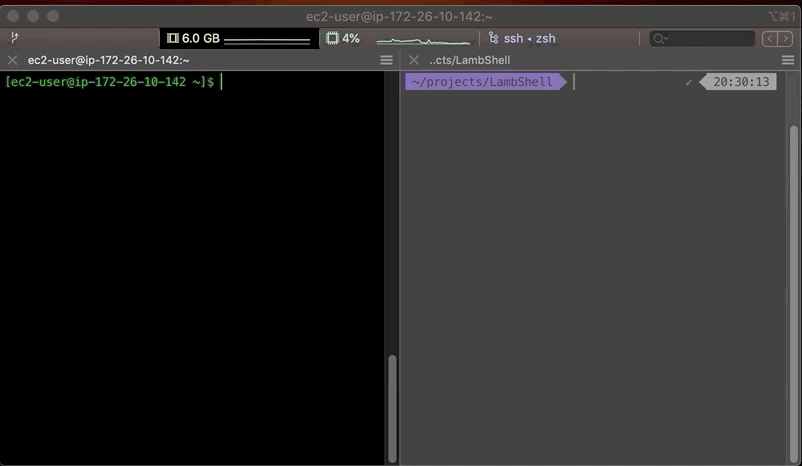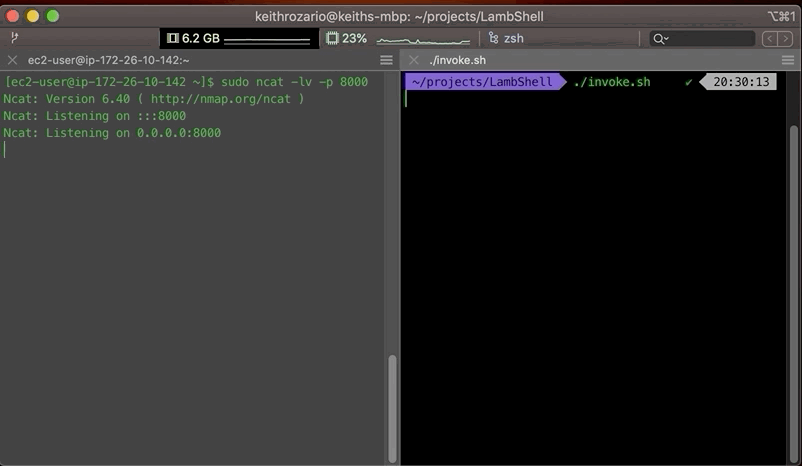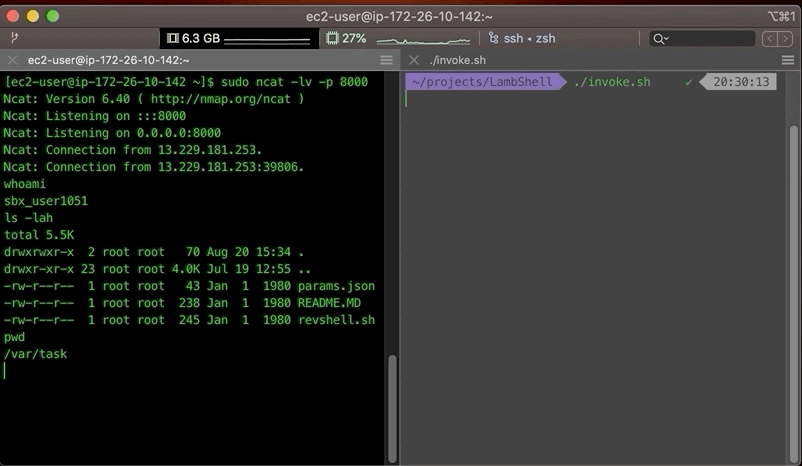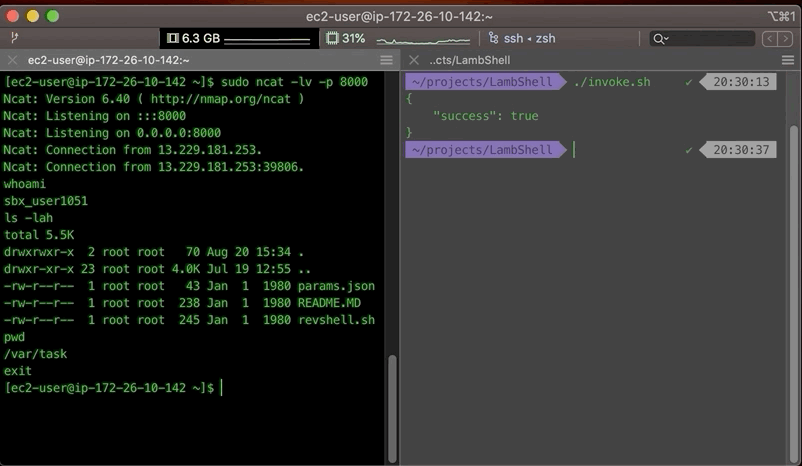
Firstly, the familiar home directory in ~/ is off-limits in a lambda function -- and I mean off-limits. There is absolutely no-way (that I know off), for you can add files into this directory. Wouldn't be a big isue, except this is where git looks for ssh keys and the known_hosts file.
Next, because lambda functions are ephemeral, you'll need a way to inject your SSH key into the function, so that it can communicate to GitHub your behalf.
Finally, because you've chosen to use the bash runtime, you're limited to the awscli utility, which while fully functional doesn't come with the usual tools as boto3 for python. It's a lot easier to loop and parse json in python than it is in bash -- fortunately, jq makes that less painful, and jq is included in the custom runtime :).
Enough talking let's build this