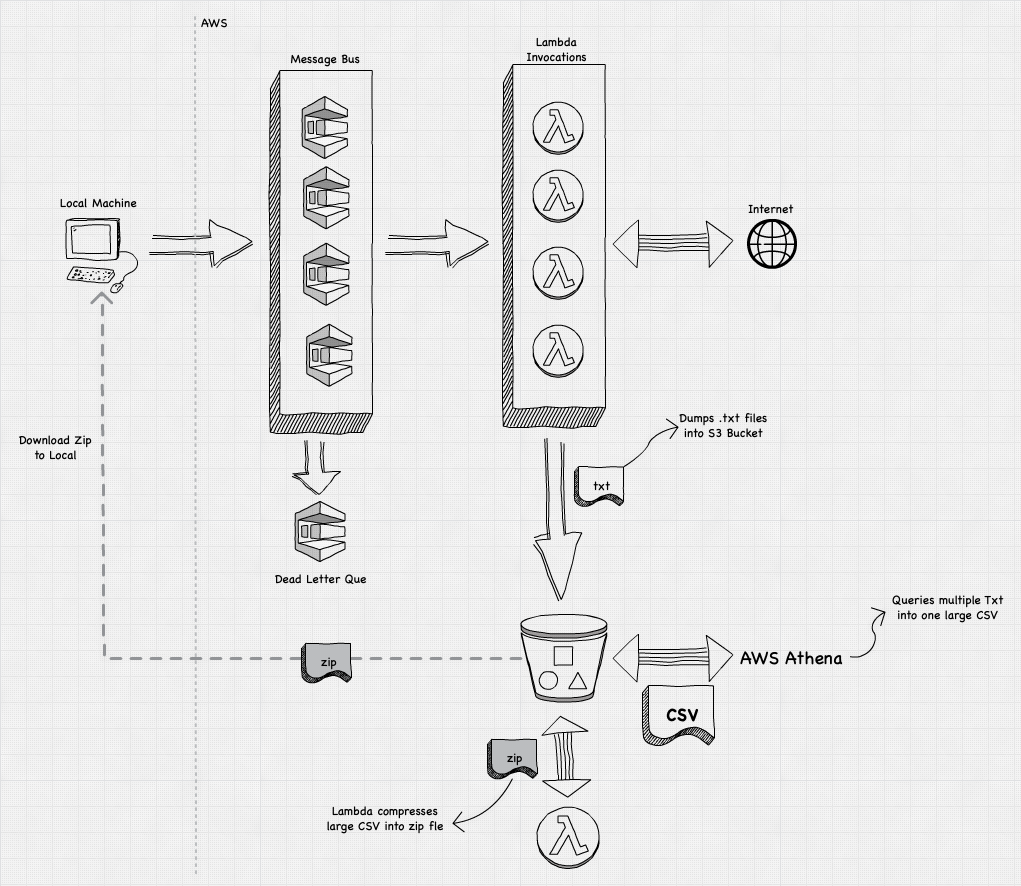
Let's look at AWS Access Keys inside a Lambda function, from how they are populated into the function's execution context, how long they last, how to exfiltrate them out and use them, and how we might detect an compromised access keys.
But before that, let's go through some basics. Lambda functions run on Firecracker, a microVM technology developed by Amazon. MicroVMs are like docker containers, but provide VM level isolation between instances. But because we're not going to cover container breakouts here, for the purpose of this post we'll use the term container to refer to these microVMs.
Anyway...
Lambda constantly spins up containers to respond to events, such as http calls via API Gateway, a file landing in an S3 bucket, or even an invoke command executed from your aws-cli.
These containers interact with AWS services in the same exact way as any code in EC2, Fargate or even your local machine -- i.e. they use a version of the AWS SDK (e.g. boto3) and authenticate with IAM access keys. There isn't any magic here, it's just with serverless we can remain blissfully ignorant of the underlying mechanism.
But occasionally it's a good idea to dig deep and try to understand what goes on under the hood, and that's what this post seeks to do.
So where in the container are the access keys stored? Well, we know that AWS SDKs reference credentials in 3 places:
- Environment Variables
- The
~/.aws/credentialsfile - The Instance Metadata Service (IMDS)
If we check, we'll find that our IAM access keys for lambda functions are stored in the environment variables of the execution context, namely:
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
- AWS_SESSION_TOKEN
You can easily verify this, by printing out those environment variables in your runtime (e.g. $AWS_ACCESS_KEY_ID) and see for yourself.
OK, now we know where the access stored keys are stored, but how did they end up here and what kind of access keys are they? For that, we need to look at the life-cycle of a Lambda function...