Recently I found myself working with an S3 bucket of 13,000 csv files that I needed to query. Initially, I was excited, because now had an excuse to play with AWS Athena or S3 Select — two serverless tools I been meaning to dive into.
But that excitement — was short-lived!
For some (as yet unexplained) reason, AWS Athena is not available in us-west-1. Which seemingly, is the only region in the us that Athena is not available on!
And…. guess where my bucket was? That’s right, the one region without AWS Athena.
Now I thought, there’d a simple way to copy objects from one bucket to another — after all, copy-and-paste is basic computer functionality, we have keyboard shortcuts to do this exact thing. But as it turns out, once you have thousands of objects in a bucket, it becomes a slow, painful and downright impossible task to get done sanely.
For one, S3 objects aren’t indexed — so AWS doesn’t have a directory of all the objects in your bucket. You can do this from the console — but it’s a snap-shots of your current inventory rather than a real-time updated index, and it’s very slow — measured in days slow! An alternative is to use the list_bucket method.
But there’s a problem with list_bucket as well, it’s sequential (one at a time), and is limited ‘just’ 1000 items per request. A full listing of a million objects would require 1000 sequential api calls just to list out the keys in the your bucket. Fortunately, I had just 13,000 csv files, so this part for fast, but that’s not the biggest problem!
Once you’ve listed out your bucket, you’re then faced with the monumentally slow task of actually copying the files. The S3 API has no bulk-copy method, and while you can use the copy_object for a file or arbitrary size, but it only works on one file at a time.
Hence copying 1 million files, would require 1 million API calls — which could be parallel, but would have been nicer to batch them up like the delete_keys method.
So to recap, copying 1 million objects, requires 1,001,000 API requests, which can be painfully slow, unless you’ve got some proper tooling.
AWS recommend using the S3DistCP, but I didn’t want to spin up an EMR server ‘just’ to handle this relatively simple cut-n-paste problem — instead I did the terribly impractical thing and built a serverless solution to copy files from one bucket to another — which looks something like this:
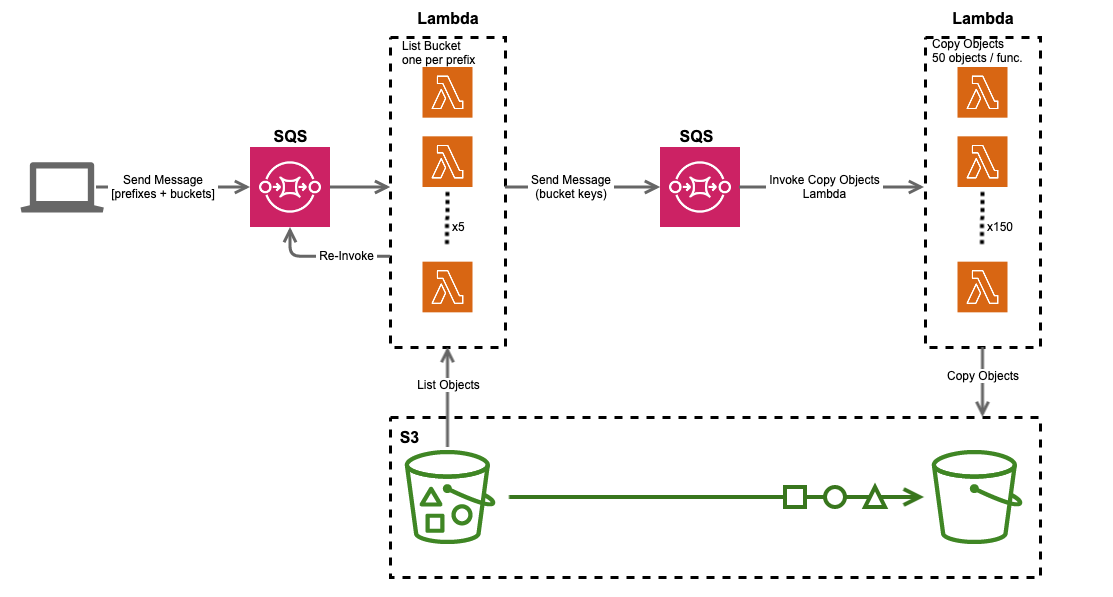
Copy them with Lambdas
Using a combination of SQS Queues and Lambda Functions, I’m able to distribute the load of those 1,000,000 api calls across a large number of lambda functions to achieve high throughput and speeds. The SQS queues help keep the whole system stable, by implementing retries and exception handling.
The program starts on your local laptop, where you send across 100 messages onto an listObjects SQS queue that invoke the list_objects function, which — well, list the objects in the bucket.
While listing out S3 objects is a sequential task, you can distribute that across ‘prefixes’ — hence you can have individual lambda functions listing out all objects in a bucket that begin with the lower-case letter ‘a’, and another function for ‘b’, ‘c’ and so on. The 100 messages, correspond to the 100 printable characters in ASCII, there’s a down-side to this approach which I explain later on in the post, but let’s continue….
If the keys in your bucket are random enough, the listing can be quite quick, as each prefix gets it’s own process. In practice it took 3 minutes to list all 1,000,000 objects in a bucket spread across just 16 lambda functions (objects were limited to hexadecimal characters). If your bucket has a more diverse set of prefixes, this would be executed far quicker.
While the lambdas are listing out the objects in our bucket, they also begin placing messages onto a separate copyObject queue — before going back to list the objects. This means, objects begin to get copied before the bucket is completely listed (more parallelism = more speed!)
As there’s no guarantee the listings would complete in the 900 second timeout window, we add additional logic for the function to invoke itself if it ever gets too close to timing out.
The function constantly checks how long it has to live (via the lambda context object) — and would place a message back onto the listObjects SQS Queue with its current ContinuationToken and exit gracefully. The SQS queue would kick off another lambda, to pick up from the ContinuationToken but with a fresh 900 second window. You can see this illustrated as the re-invoke line on the diagram above, and here’s a snippet of the code that actually does this:
Later on I’ll explain why we use queues instead of invoking the lambda recursively, but for now let’s move onto the actually copying of objects.
The copy_objects function is invoked from the copyObjects queue. Each message has a total of 100 keys (default setting), which the function loops through and runs the copy_object method on. Fortunately, the method doesn’t download the file to disk — so even 128MB lambda can copy a 3GB file with ease, you just have to give it enough time to complete.
In practice we could copy 100 files in ~6 seconds, depending on size) and provided both buckets were in the same region. The real power comes from spinning up plenty of them in parallel, but even s3 has limits, so be careful.
I got 150 lambdas to give me a throughput of 22,500 files per second — the maximum throughput of your s3 bucket is dependent on the number of prefixes (folders in S3 parlance) you have, spinning up too many lambdas will spit out too many exceptions because S3 will begin throttling you!
All-in-all copying a million files from one bucket to another, took 8 minutes if they’re in the same region. For cross-region testing, it 25 minutes to transfer the same million files between us-west-1 and us-east-2. Not bad for solution that would fit easily into your free AWS tier.
To be clear, the files are tiny — 4 Bytes each, but in general, even 100 large-ish files should be transferable in under 900 seconds.
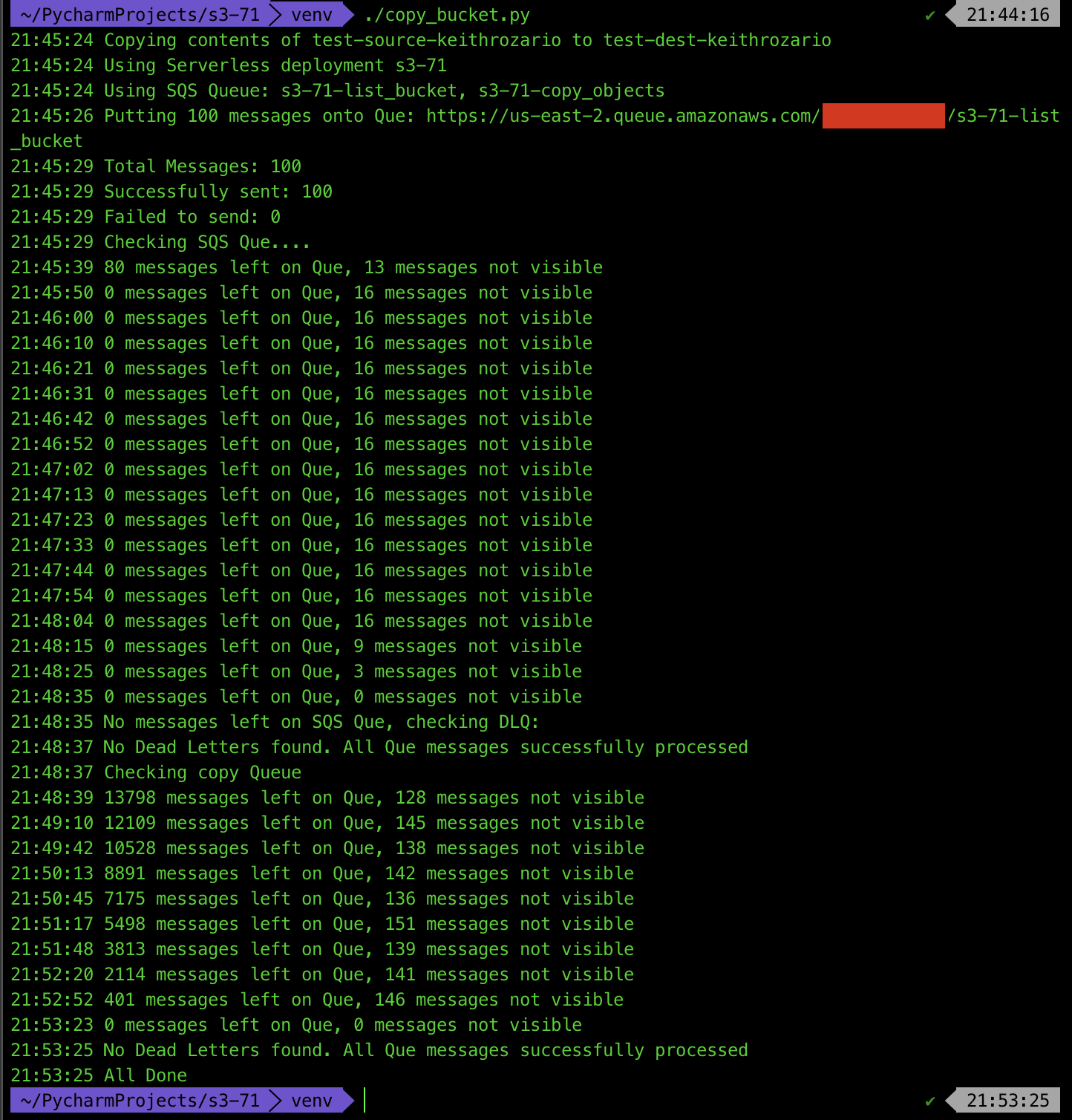
The results look like this:
So why use a Queue
At this point it’s worthwhile to ask why use an SQS Queue, when we can invoke the lambda directly. The answer, SQS can do the following :
- Gradual Ramp up
- Re-try functionality
- Exception Handling
- Recursive Lambda invocation
Using an SQS we’re able to scale our lambda invocations up in an orderly fashion, which allows our back-ends (e.g. DynamoDB or S3) to also scale up in tandem. Instantly invoking 800 lambdas to read an S3 bucket is a recipe for a Throttling and the dreaded ClientError
If you ever get Throttled and the lambda exits, SQS can invoke a re-try based on a specific policy. Hence all lambdas get a chance to complete, with failed lambdas being retried, and completed lambdas having their messages removed from the Queue — this is all amazing stuff, and yet another reason why SQS triggers for lambda’s are the way to go.
Thirdly, SQS allows for wonderful exception handling — if the message has been retried too many times, you can have it redirected to a Dead-Letter-Queue. This is where messages that have been retried too many times go to die — in other words in a single place to view messages that failed to process.
Finally, SQS allows for a more managed recursive invocation of a lambda. Rather than have the lambda call itself (and find yourself unable to control an infinite recursion) — you can have the lambda simply put a message on a SQS queue that calls itself. The benefits are getting all the 3 points above, but also you can halt all lambas by simply purging the queue.
Caveats
We spread the listing load, by listing all objects beginning with a certain character — as a default we only consider the printable ascii characters.
This approach has a major drawback — as S3 allows for objects to have names that begin with any utf-8 character (all ~1 Million of them!). This means that if you have objects that begin with ® or ø, the program won’t pick them up. It’s on my to-do list to solve this problem — just not now.
Conclusion
The code is available on github here.
I think serverless is a perfect approach for embrassingly parallel problems like this, and the combination of SQS Queues + Lambdas just make serverless solutions far more robust in terms of monitoring, exception handling and scaling.