
Over the past few weeks, I’ve been toying with lambda functions and thinking about using them for more than just APIs. I think people miss the most interesting aspect of serverless functions — namely that they’re massively parallel capability, which can do a lot more than just run APIs or respond to events.
There’s 2-ways AWS let’s you run lambdas, either via triggering them from some event (e.g. a new file in the S3 bucket) or invoking them directly from code. Invoking is a game-changer, because you can write code, that basically offloads processing to a lambda function directly from the code. Lambda is a giant machine, with huge potential.
What could you do with a 1000-core, 3TB machine, connected to a unlimited amount of bandwidth and large number of ip addresses?
Here’s my answer. It’s called potassium-40, I’ll explain the name later
So what is potassium-40
Potassium-40 is an application-level scanner that’s built for speed. It uses parallel lambda functions to do http scans on a specific domain.
Currently it does just one thing, which is to grab the robots.txt from all domains in the cisco umbrella 1 million, and store the data in the text file for download. (I only grab legitimate robots.txt file, and won’t store 404 html pages etc)
This isn’t a port-scanner like nmap or masscan, it’s not just scanning the status of a port, it’s actually creating a TCP connection to the domain, and performing all the required handshakes in order to get the robots.txtfile.
Scanning for the existence of ports requires just one SYN packet to be sent from your machine, even a typical banner grab would take 3-5 round trips, but a http connection is far more expensive in terms of resources, and requires state to be stored, it’s even more expensive when TLS and redirects are involved!
Which is where lambda’s come in. They’re effectively parallel computers that can execute code for you — plus AWS give you a large amount of free resources per month! So not only run 1000 parallel processes, but do so for free!
A scan of 1,000,000 websites will typically take less than 5 minutes.
But how do we scan 1 million urls in under 5 minutes? Well here’s how.
Inner workings
You can download the code and try it yourself here
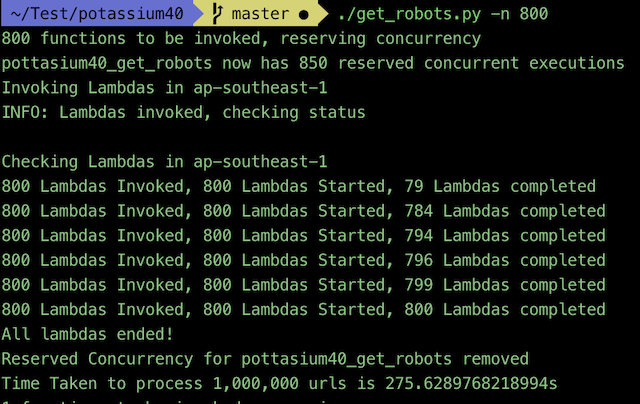
After installation you can run the get_robots -n 800script, which asynchronously invokes 800 lambdas, with each lambda requesting the robots.txt file from 1,250 sites.
After much testing, I learnt that the best way to rapidly invoke hundreds of functions at once is to first reserve the concurrency for the specific function, guaranteeing there’s enough free executions in your account to accept the downpour of invocations. The tool uses multiple processes to invoke the functions which allow for all 800 lambdas to be invoked in ~20s (depending on latency)
The lambda’s are invoked asynchronously, which means that the calling application (the script on your local machine) receives a 202 status almost immediately after invoking it, without waiting for the lambda to complete.
Unfortunately, that means the output the function cannot be returned to the calling application. This is done intentionally to improve performance — but it introduces many challenges which we’ll go through later.
Boto3, which is the python SDK for AWS, uses a blocking function to invoke lambdas — each invocation can only happen after the previous one has completed, some have tried to write their own custom asynchronous invocation call, but I thought it best to stick with the official AWS SDK.
Next, within each function, we run 125 processes, based on some loose testing I did, 125 is the perfect number for a 1.2GB function. And yes, lambda functions can be multi-process! But not with the usual Queues or Pools that most are familiar with, instead we have to use pipe().
Note of caution, the code provided in the AWS blog here has an error — if you pass a large enough object to the calling function, it **will** result in a deadlock condition, I spent hours troubleshooting this, till I found the solution here.
Once all processes are initialized, the functions make their http requests using the python requests module. This is an extremely versatile module, that’s purpose built for http-requests it’s even recommended in the python documentation — it’s as close to an official module as one can get. We all need to be careful over what libraries/modules/packages we import into our code — but I trust the requests package.
The biggest challenge was monitoring the functions. Because we request them asynchronously, we needed a way to check if each invocation has started, is in progress or has ended. To do this, we poll the CloudWatch logs for lambda invocations, to check the number of started and ended lambda invocations within a given time period, it’s not very elegant, but gets the job done. If you know a better way, let me know — please!!!
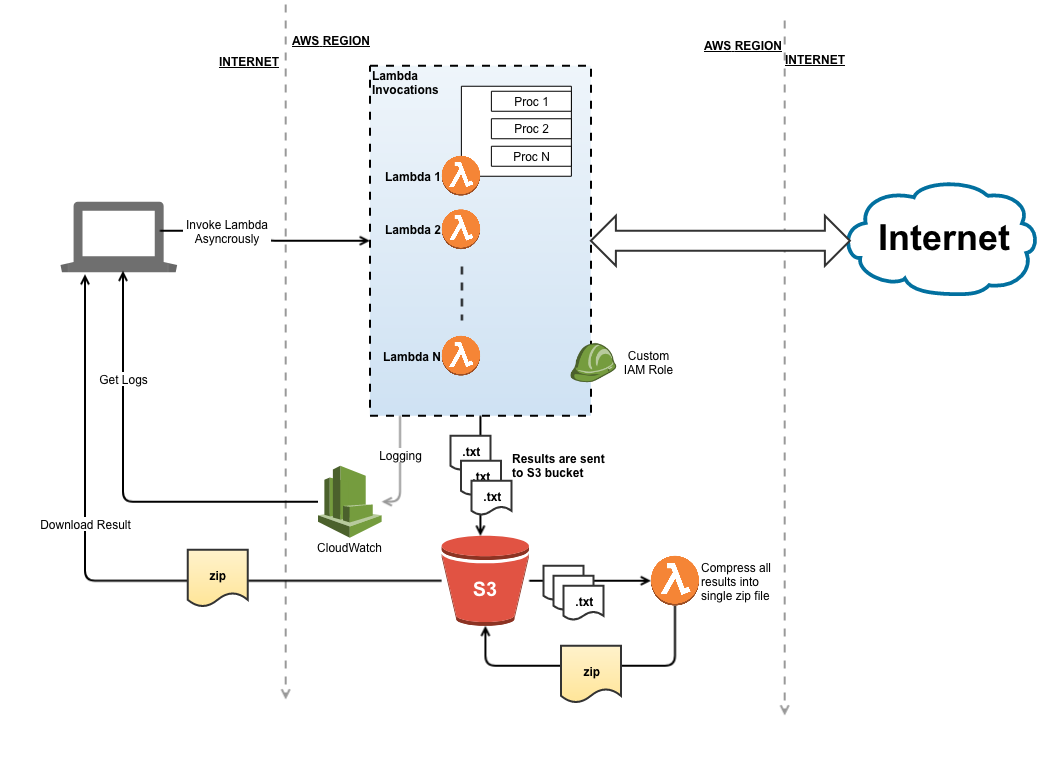
Finally, each function places a json file into the s3 bucket, think of the bucket as temporary storage of the function’s return result. The json file is a flat array of json objects that look like this:
[{“domain_1”: “abc.com”, “robots.txt”: “User-Agent:…”},
…….
{“domain_2”: “def.com”, “robots.txt”: “User-Agent:…”}]
Once all functions have finished, the script then invokes the potassium40_compress_bucket lambda function, that reads in all ~800 files from the bucket, consolidates them into a single file (by simply appending them to each other), compresses them back into a zip, and uploads the data back into the bucket.
Spending a fraction of cent to run this function that reduces the number of files and the size of the data, is worth the effort in lieu of downloading 800 uncompressed files. I spent some time engineering the function to perform all task in memory. Lambda functions have 512MB of disk space in the /tmp directory, but since this was a 3GB function, using memory would have been faster, but only marginally. I use 3GB to get the most CPU power, as AWS allocate CPU in proportion to the memory of the function.
In the end, a scan of 1 million websites would take less than 5 minutes, with the compression another 2 minutes after that. Hence, scanning 1 million websites, and grabbing their robots.txt file would take 7 minutes in total. Not bad!
Eventually you end up with an architecture that looks like this
But what about cost I hear you ask. Surely spinning up 1TB of memory within 800 different processes is going to break the bank. Well actually…
Cost
So let’s break this down, the most expensive cost is going to be running the lambda functions themselves, here’s some metrics from a run I did earlier today:
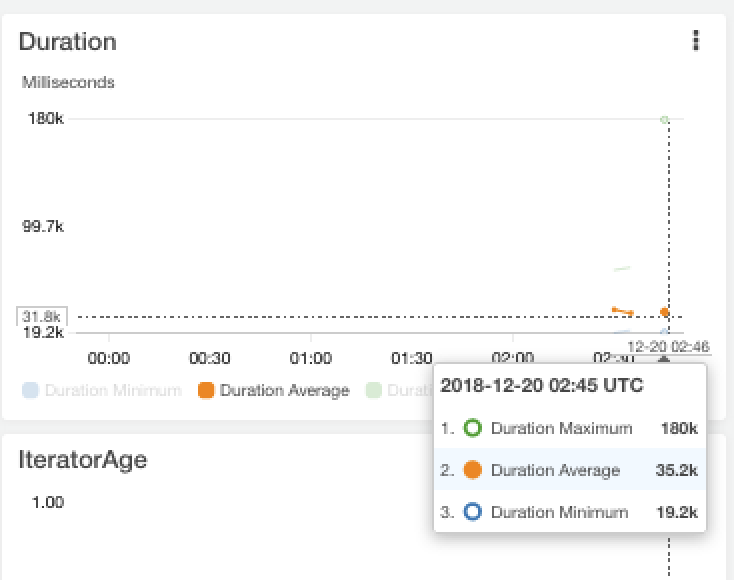
These were 800 lambda invocations, with an average duration of 35.2 seconds (the metrics are in milliseconds).
Each lambda by default is allocated 1280MB of memory. AWS charge $0.00001667 per Gigabyte-second of execution time, hence for 800 lambdas running an average of 35.2 seconds, the total cost would be:
1280/1024 GB * 35.2 Seconds * 800 parallel Lambdas * 0.00001667) = $0.60
AWS give you 400,000 Gigabyte-seconds per month for free, which means you can run this scan 10 times a month for free!
I limit each lambda function to 180 seconds of execution time, this will incur 1-2 errors, as some functions take an unexplainable amount of time.
Also some folks, basically kill robots by serving up large random content for every bot requests. This is bad etiquette as robots.txt is a file built for robots, but alas, we have to cope with this by sacrificing some them.
This means we’d lose around results from 1-2 functions. But that’s just 0.25% of the 800 functions that were invoked, many fast scanners like zmap are prepared to lose this level of accuracy at the price of speed, and so am I.
I might reduce the error rate, by allowing the function to run for the maximum 15 minutes — by why double, triple, or quadruple my scan time just to increase the accuracy by 0.25%?!
Next, since S3 buckets charge per Gigabyte-Month, which is calculated as the average Gigabyte-hours per month, the total cost of using the bucket is actually a fraction of 1 cent per scan. I did the calculations, so trust me 🙂
Had we used DynamoDB, which would have been much easier to extract — but we’d also have incurred about 40-50 times more cost. Sure it goes from 1 cent to 40 cents, but that kind of magnitude severely limits the scalability of the scan. In the future I may use DynamoDB, just to make this more manageable — but again, why store the data in DynamoDB if we’d just dump it out into a zip file? Plus I’m not if DynamoDB could cope with a sudden surge of volume?
The last two cost are also quite irrelevant, which include the egress data out of the function (you pay for all http requests) and the cost of the Cloudwatch logs storage. Together they’re less than 1 cent of charges as well (since incoming data is free!), and the outgoing requests is quite small.
So a scan of 1 million websites, would cost less than 60 cents, much less than a cup of coffee here in Singapore 🙂
Conclusion
It’s a great way to end the year by making something you’re proud off. I skipped a lot of details about the build, like how I used lambda layers for the first time, and how the undeploy.py script will actually delete even the Cloudwatch logs to leave your AWS account without a single trace of potassium-40 (it’s radioactive after all).
Also, I run the scan on a randomized list of the cisco umbrella top 1 million, to avoid lumping domains by popularity or latency. Zmap run similar strategies to ensure each parallel process receives a representative sample.
Next year, I’m going to try to refactor the requests package out of the function and into it’s own layer, giving me far more flexibility, plus maybe include DynamoDB.
So why call it Potassium-40?
Lambda is symbol for the decay constant of radioactive isotopes, and potassium-40 is one such radioactive isotope . But what really seals the deal is potassium has the chemical symbol of K, which is both the first letter of my name, and the mathematical symbol for 1000 (albeit small k for kilo), which is the maximum number of concurrent functions per region that AWS allows.